
BaseModel vs TIGER for sequential recommendations

In December 2023, a paper titled "Recommender Systems with Generative Retrieval" [1] was presented by researchers at NeurIPS 2023. This paper introduced a novel recommender system, referred to as 'TIGER,' which garnered significant attention due to its innovative approach and state-of-the-art results in sequential recommendation tasks.
Overview of TIGER
The TIGER architecture incorporates several cutting-edge techniques and has a number of interesting properties:
- Generative, autoregressive recommender system.
- Transformer-based encoder-decoder architecture.
- Item representations using "Semantic IDs," which are tuples of discrete codes.
- A residual quantization mechanism (RQ-VAE) for item representation.
- Achieved state-of-the-art results on benchmark datasets, surpassing previous models significantly.
Details of TIGER’s Architecture
The TIGER model leverages RQ-VAE to generate sparse item representations, a method well-suited for transformer decoders where suffix codes depend on prefix codes. The model architecture includes a Bidirectional Transformer Encoder to aggregate historical interactions and an Autoregressive Transformer Decoder to predict the next item in a sequence.
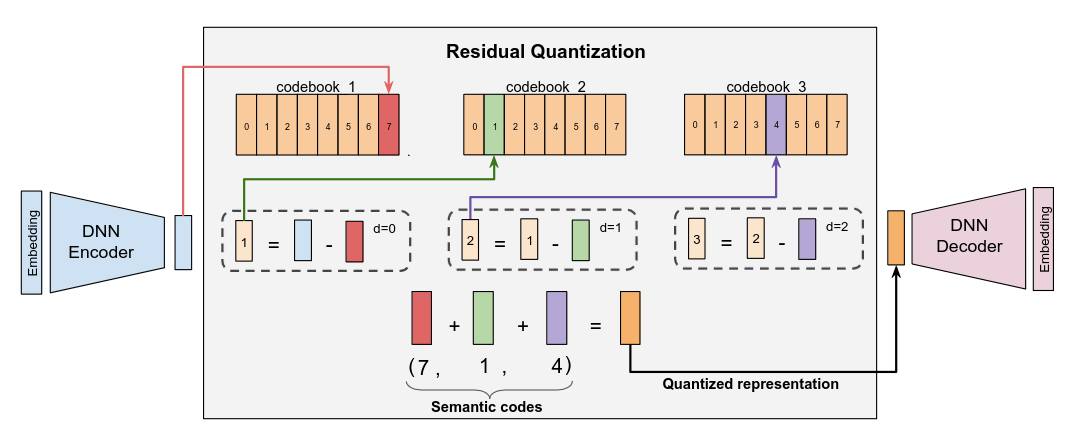
The whole architecture looks as follows:
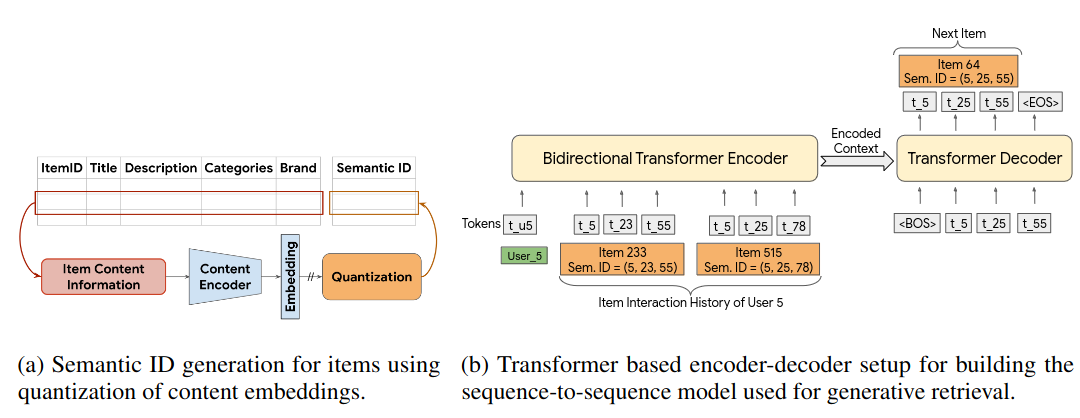
On the left-hand side of TIGER, RQ-VAE item code generation can be seen. The right-hand side is the core neural architecture for autoregressive modeling. It consists of a Bidirectional Transformer Encoder, aggregating historical interactions, and an autoregressive Transformer Decoder, proposing the next item in the sequence as a sequence of residual codes.
TIGER’s Benchmark Results
TIGER was benchmarked on several Amazon datasets:
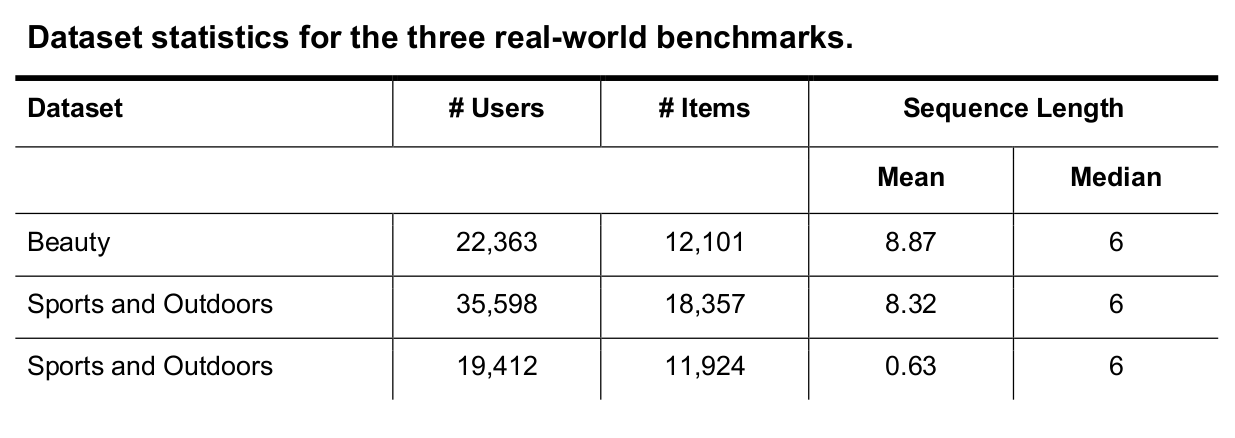
TIGER outperformed prior strong baselines on the Amazon datasets used. Results below:
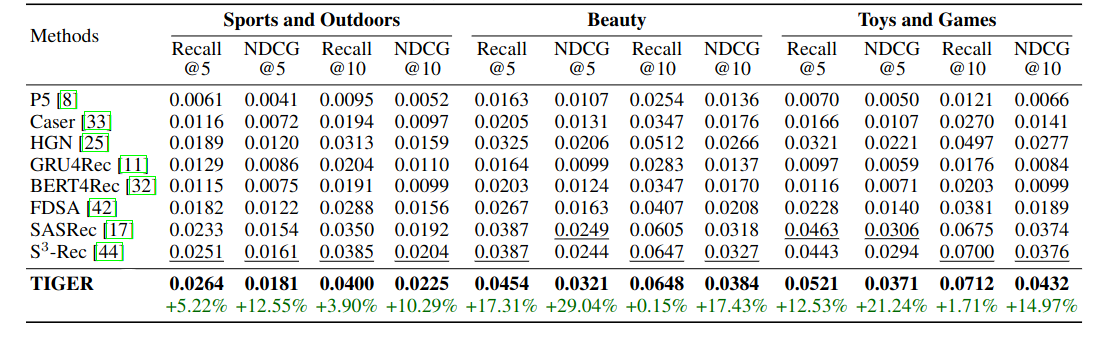
TIGER was able to achieve significant improvements of +0.15% to +29.04% over prior state-of-the-art on all metrics on all datasets.
BaseModel vs TIGER Architecture
BaseModel, shares some conceptual similarities with TIGER, such as autoregressive modeling and sparse integer tuple representation of items. However, there are significant differences in their implementation:
- Item Representation: BaseModel uses EMDE 2.0 for item representation instead of RQ-VAE, with independent item codes rather than hierarchical ones.
- Model Architecture: BaseModel employs a proprietary neural network designed to maximize data efficiency and learning speed, differing from TIGER’s transformer architecture.
- Inference Method: BaseModel performs direct predictions, avoiding the computationally expensive beam-search decoding used in TIGER.
BaseModel vs TIGER Performance
To evaluate BaseModel against TIGER, we replicated the exact data preparation, training, validation, and testing protocols described in the TIGER paper. The exact same implementations of Recall and NDCG metrics were used for consistency.
For comparison of the models a few steps were performed:
- Implementation of the exact data preparation protocol as per TIGER paper.
- Implementation of the exact training, validation, and testing protocol as per TIGER paper.
- Sourcing the exact implementations of Recall and NDCG metrics used in TIGER and incorporation into BaseModel.
- Model training and evaluation (on all 3 datasets).
The entire process took 3 hours from scratch to finish. The parameters of BaseModel were not tuned in any way, and the results look as follows:
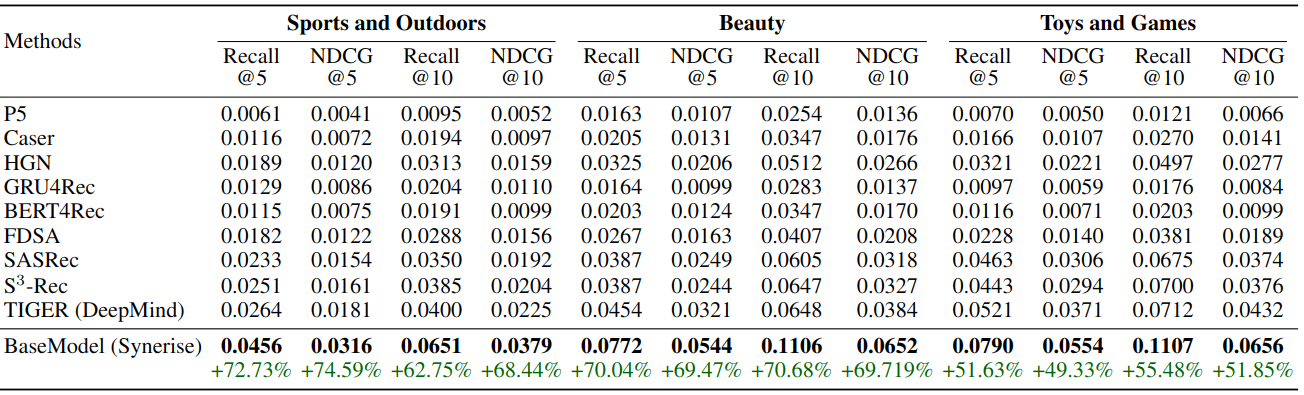
Despite limited optimization of BaseModel’s parameters, the results are quite compelling. BaseModel achieved a further +24.26% to +61.57% improvement over TIGER’s results on the same datasets.
Given TIGER’s reliance on RQ-VAE, costly Transformer training, and beam-search inference, it is reasonable to infer that BaseModel’s training and inference processes are orders of magnitude faster.
Conclusion
The comparison between BaseModel and TIGER reveals substantial differences in their architectural choices and performance. While TIGER represents a notable advancement in generative retrieval recommender systems, BaseModel’s approach demonstrates superior efficiency and effectiveness in sequential recommendation tasks. Further optimization and exploration of BaseModel could lead to even more significant advancements in the field of recommender systems.
The potential of our methods encourages continued innovation and comparison with leading models in the field to push the boundaries of what behavioral models can achieve.
References
[1] Rajput, Shashank, et al. "Recommender systems with generative retrieval." Advances in Neural Information Processing Systems 36 (2024).