
Enhancing Streaming and Request Handling Efficiency with gRPC and Coroutines: Part 2
Explore how to handle thousands of workers (2,160 and growing) using gRPC, coroutines, and asynchronous communication.

Background
In the previous article, we delved into the implementation of a ThreadPool, a coroutine framework, and the creation of a gRPC server for handling requests from the gateway. Now, let me demonstrate how we create the client side for sending requests to the workers.
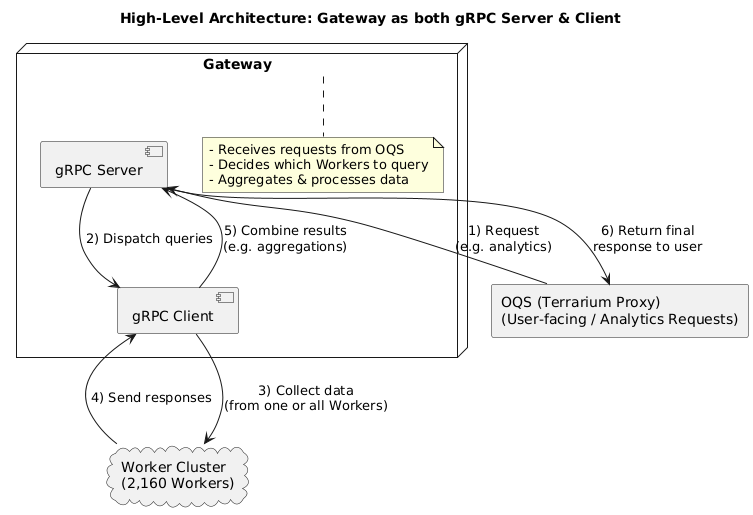
For user-facing queries, we fetch data from a single worker. However, for analytics (OLAP workload), we need to retrieve data from all 2,160 workers—this number is merely an example, and the architecture can be scaled as required. Operating as both a server and a client, the gateway receives requests from OQS, an internal TerrariumDB proxy for request dispatching; then, as a client, it determines the selection of workers to query for data. Once all responses are received, the gateway processes them into the final result. In the meantime, the gateway can engage in diverse calculations on the data, such as reductions (e.g., calculating total income for a given period).
The most challenging aspect will be ensuring a smooth flow of threads while the gateway waits for responses. Our aim is to handle requests from OQS, while concurrently querying workers for data, performing complex reductions, and transmitting refined results—a feat made possible through the use of coroutines and an asynchronous server/client model.
Protobuf structure
First, we need to understand how to send a request using gRPC. Each request must have a corresponding protobuf structure, which can include various data types (e.g., string, int, bool) and can even contain repeated fields or maps.
We need to define the structure of both the Request and the Response, and also create a Service class that outlines all available methods. For example, if we want to send a request with two fields—message (a string) and id (an integer)—and receive a response with a single message field (a string), we define this in the protobuf structure. After defining the structure, we must specify the service methods. In this case, we’ll create a method called Handle that takes a Request and returns a Response. Listing 1 provides the complete definition.
message Request {
string message = 1;
int id = 2;
}
message Response {
string message = 1;
}
service Worker {
rpc Handle(Request) returns(Response) {}
}Listing 1. Example protobuf structure for a single Handler request.
Having a worker service, we can create a necessary client and send simple message using gRPC library:
Request request;
Response response;
grpc::ClientContext context;
auto clinet = Worker::NewStub(grpc::CreateChannel(
url, grpc::InsecureChannelCredentials()));
const auto status =
client->Handle(&context, request, &response);
if (!status.ok()) {
std::cout << "Failed!\n";
} else {
std::cout << "Result: " << response.message() << '\n';
}Listing 2. Example request sent by a client
Client side requests
The implementation in Listing 2 turned out to be highly inefficient, as it blocks until we get a response. To reduce unnecessary thread switching, we should avoid blocking threads solely for response waiting. Another drawback is that we have 2,160 workers but only 64 threads, meaning we are restricted to querying only 64 workers simultaneously. A better approach would be to query all workers at once and wait for their responses on a completion queue. This can be achieved by implementing asynchronous communication on the client side, building upon the approach covered in the previous article. First, we need to create a Worker class, which will own the channel. Next, we will define a class responsible for sending requests to the workers and managing the completion queue. This will allow us to break the request into smaller stages: sending the request, receiving the response, and completing the process. Since we have 2,160 workers, we want to implement multiple completion queues to distribute the workload, similar to how we handle it on the gateway server.
class Worker
{
public:
// Assaign completionQueue to a worker
init(grpc::CompletionQueue* cq);
// Return an awaitable which lets you use
// coroutine mechanism for waiting for a request.
std::shared_ptr<Awaitable<Response>>
request(const Request&);
private:
WorkerID id; // Identified worker
std::unique_ptr<Worker::Stub> client;
grpc::CompletionQueue* cq;
};Listing 3. Worker class.
class WorkersManager {
public:
std::shared_ptr<Awaitable<Response>>
requestWorker(WorkerId, const Request&);
std::vector<std::shared_ptr<Awaitable<Response>>>
requestAll(const Request& request);
private:
std::vector<std::unique_ptr<grpc::CompletionQueue>> queues;
std::unorederd_map<WorkerId,std::unique_ptr<Worker>> workers;
};Listing 4. WorkerManager class.
The WorkerManager class creates 2,160 workers and manages several completionQueues (currently we use 16, based on benchmark result). It includes two methods:
- requestWorker, which allows querying a single worker.
- requestAll, which queries all workers at once.
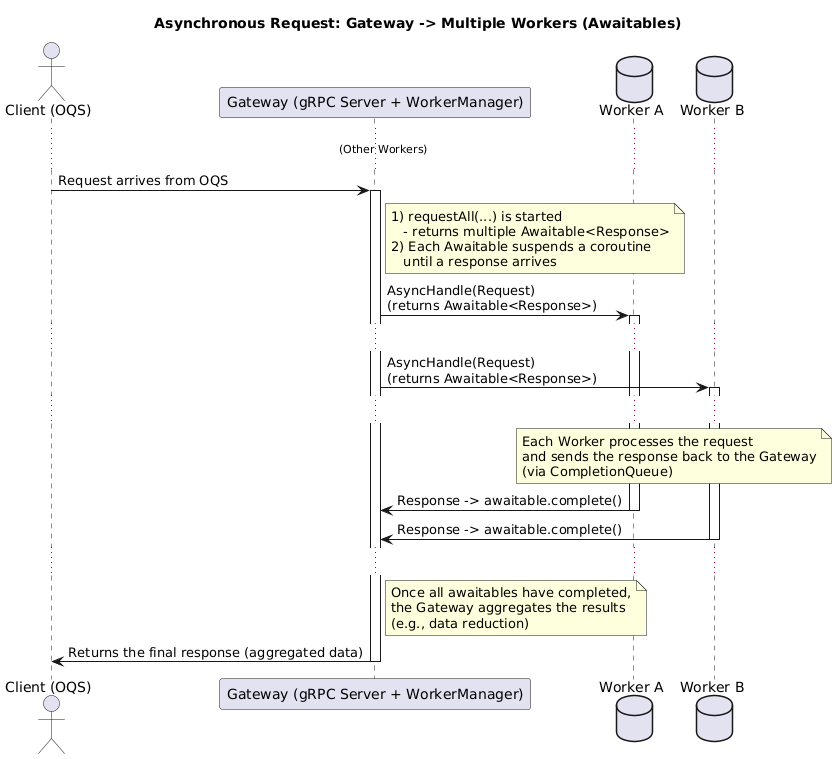
To support coroutines, these methods return an awaitable object that suspends the function until the result is available. This mechanism enables us to query all workers simultaneously, as opposed to the previous limit of 64, resulting in a substantial acceleration of the process.
The next step is to implement the request method for a worker, which will asynchronously call a method and return an awaitable object containing the response. Since the request is asynchronous, we need to manage the lifecycle of local variables required to send the request, such as status, response, and context. To handle this, we wrap these variables inside a RequestContext class. The awaitable object allows us to co_await the response and complete the request once we receive the worker's response.
Class RequestContext {
public:
RequestContext(std::shared_ptr<Awaitable<Response>>,
/* other necessary data */ );
Awaitable<Response>& awaitable() {
return awaitable;
}
const Response& response {
return response;
}
void asyncHandle() {
context = std::make_unique<grpc::ClientContext>();
// Initialize a request
responder = client.AsyncHandle(&context, request, cq);
// As a tag we send this because we want to reuse this
// class when we receive a response
responder->Finish(
&response, &status, reinterpret_cast<void*>(this));
}
private:
using Reader = grpc::ClientAsyncResponseReader<Response>;
std::shared_ptr<Awaitable<Response>> awaitable;
std::unique_ptr<grpc::ClientContext> context;
grpc::Status status;
Response response;
std::unique_ptr<Reader> responder;
};Listing 5. Class RequestContext. `
std::shared_ptr<Awaitable<Response>> request(const Request& request) {
auto awaitable = std::make_shared<Awaitable<Response>>();
// We need to manually manage the lifetime of request.
// That's why we put this class in asyncHandle as a tag.
// When request finishes, we will get it from
// completion queue and we can delete it
RequestContext* requestContext =
new RequestContext(awaitable, /*all necessary data*/);
requestContext->asyncHandle();
return awaitable;
}Listing 6. Sending an asynchronous request
The final step is to implement a function inside the WorkerManager class that handles a CompletionQueue. We will create multiple queues to distribute the payload evenly. Additionally, we need to ensure that requests are deleted once they are completed, to avoid memory leaks (since we manually allocate the RequestContext in the worker's request method). Each queue should be assigned to a dedicated thread to efficiently manage the workload. Instead of manually allocating memory, we can use std::shared_ptr, which will automatically release the object when the last reference (i.e., the last corresponding std::shared_ptr) is destroyed. I will demonstrate this approach in the upcoming article, where we will focus on the worker side.
for (size_t i = 0; i < NUMBER_OF_QUEUES; ++i) {
queues.emplace_back(
std::make_unique<grpc::CompletionQueue>());
threads.emplace_back([this, cq = queues.back().get()]() {
void tag;
bool ok;
while (cq->Next(&tag, &ok)) {
RequestContext* requestContext =
static_cast<RequestContext*>(tag);
auto task = [requestContext]() {
// get corresponding awaitable
auto& awaitble = requestContext->awaitable();
// This function must run on a separate thread,
// because when we call complete.
// We will resume a coroutine.
// So we don't want to block queue thread
awaitable.complete(requestContext->response());
// Free memory after finish a request
delete requestContext;
};
threadPool.push_task(std::move(task));
}
});
}Listing 7. Handling a request by using completion queue.
In summary, when requesting data from one or more workers, we generate an awaitable object that pauses the function until a response is received. By employing coroutines, we can dispatch 2,160 requests, even with just 64 threads, as we do not obstruct the entire thread. Instead, the coroutine can be reactivated on any accessible thread once a response is received and the awaitable object's complete function is invoked.
Task<void> handleSomething(const std::string& messageRequest) {
Request request;
request.set_message(messageRequest);
auto awaitable =
workerManager.requestWorker(WorkerId(42), request);
// Here we suspend until we get a response
Response response = co_await *awaitable;
}Listing 8. Sending a request to a worker and waiting for a response
Error handling and deadlines
In real-world scenarios, we may encounter various errors such as:
- Lost connection
- Malformed request
- Missing client with a specific ID
- Incorrect method
- Insufficient parameters for a function
- Application crashes, etc.
The previous implementation doesn't handle most of these issues. For instance, if there is a connectivity issue with the server, gRPC responds with an error status and error code, resembling a scenario when a method (like Handle) is missing. However, current setup lacks support for handling issues like malformed requests or missing client IDs. These errors aren't related to gRPC itself, but they are result of how we process and handle requests. Let's focus on the gRPC side and extend the implementation to include error handling.
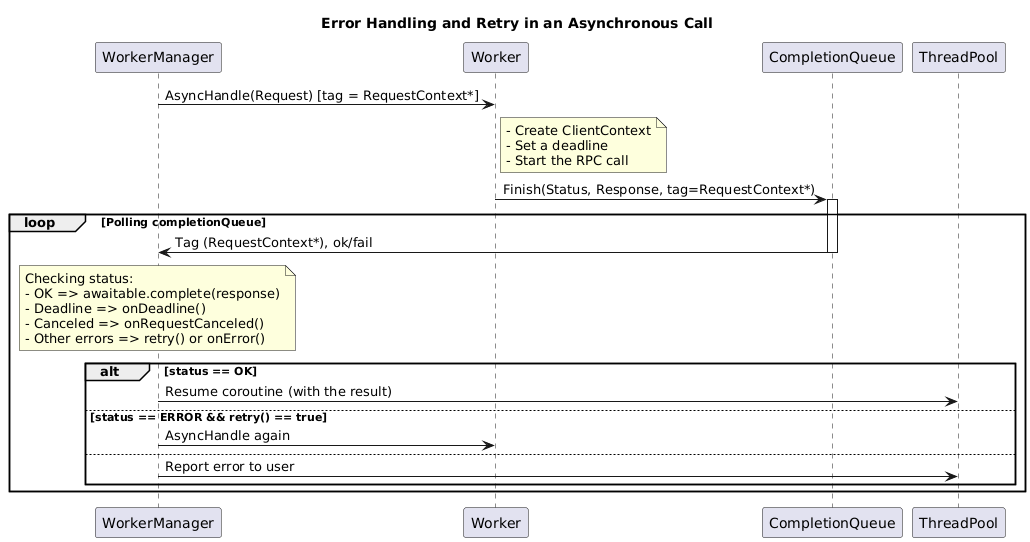
The initial action is to set a time limit for queries to prevent system slowdowns caused by prolonged waits for responses that may never come, such as instances when a worker binary crashes or gets stuck in an infinite loop due to a bug.
void asyncHandle(
std::chrono::time_point<std::chrono::system_clock> deadline) {
context = std::makeunique<grpc::ClientContext>();
// Set deadline to gRPC client context.
// If deadline is reached,
// the request will stop and we will get the error
// in a completion queue. We don't need to
// manage deadline by own
context->set_deadline(deadline);
responder = client.AsyncHandle(&context, request, cq);
responder->Finish(
&response, &status, reinterpret_cast<void*>(this));
}Listing 9. Set deadline to gRPC request.
Next, we want to retry the request when failed. We don't want to send an error every time. Instead, let's consider implementing a strategy where, for example, after five attempts, we prompt the user with a user-friendly message, such as "Unable to establish connection with the worker" or "Connection interrupted while processing the query." This approach ensures that users are notified effectively without flooding them with repeated error messages.
bool retry() {
if (++_retryCounter > maxRetires) {
return false;
}
// Retry request with a given deadline
asyncHandle(deadline);
return true;
}Listing 10. Add a retry option to RequestContext
Finally, we can extend the completionQueue code to incorporate error handling for various scenarios. In cases where a deadline is reached, we don't want to retry the request – this situation often signals a critical issue such as a worker being overloaded or the application due to compaction process or heavy RAM usage. If the request is canceled, we should notify the caller. For other errors, we want to retry the request, as temporary issues like a brief connection loss or a network layer problem might resolve themselves and not occur again.
while (cq->Next(&tag, &ok)) {
RequestContext* requestContext =
static_cast<RequestContext*>(tag);
threadPool.pushtask([requestContext]() {
auto& awaitble = requestContext->awaitable();
const grpc::Status& status = requestContext->status();
// get grpc::Status and check if we send
// and receive a request properly
if (status.ok()) {
awaitable.complete(requestContext->response());
delete requestContext;
return;
}
const auto code = status.error_code();
// Request takes too long
if (code == grpc::StatusCode::DEADLINE_EXCEEDED) {
// Notify a user about deadline exceeded
onDeadline(requestContext);
} else if (code == grpc::StatusCode::CANCELED) {
// Request was canceled (eg: Server shudown).
// We want to immediately finish requests
onRequestCanceled(requestContext);
} else if (!requestContext->retry()) {
// We can't connect or connection was broke.
// If we can't retry request (retry too many times)
// send an error to a user
onError(requestContext);
}
});
})Listing 11. Error handling by completion queue
Error handling for malformed requests or incorrect parameters depends on the way we implement the request processing, as there is no one-size-fits-all solution. We can first validate the request and send an error response if it's malformed. If the worker returns an error, we can propagate that error to the user, and similarly handle other potential issues as they arise.
Conclusion
In this article, we explored methods for optimizing streaming and request handling using gRPC and coroutines, with particular emphasis on the client-side approach. By leveraging asynchronous communication, we were able to address the challenges posed by handling a large number of workers (2,160 and growing) while minimizing thread blocking and maximizing concurrency. The use of coroutines allows us to send and process requests simultaneously without being constrained by the limited number of threads. Such architecture allow as to scale while load is growing without needed to set up new virtual machines (which generate additional costs).
We also introduced a more robust error handling mechanism, including support for timeouts, retries, and handling specific error conditions like connection losses or request cancellations. These improvements ensure that the system remains responsive and resilient, even in the face of network or worker-side failures.
By integrating these advanced concepts, we can efficiently manage large-scale distributed systems, making them faster, more reliable, and better equipped to handle real-world operational challenges. In the upcoming article, we will shift our focus to the worker-side implementation, where we will expand upon these principles to refine and enhance the overall request-response process.
Mateusz Adamski, Senior C++ developer at Synerise