
Towards a multi-purpose behavioral model

In various subfields of AI research, there is a tendency to create models which can serve many different tasks with minimal fine-tuning effort. Stanford researchers introduced the concept of foundation models, which are trained on massive datasets and can be adapted to different downstream applications. We may think this way about transformer-based models like BERT or GPT. They are pre-trained on huge datasets with a language modeling objective and can be fine-tuned for various NLP tasks such as text classification, sequence labeling, or translation. Also, in the field of vision, big models trained on large sets of data in the image recognition task are fine-tuned on smaller domain-specific datasets like medical image classification.

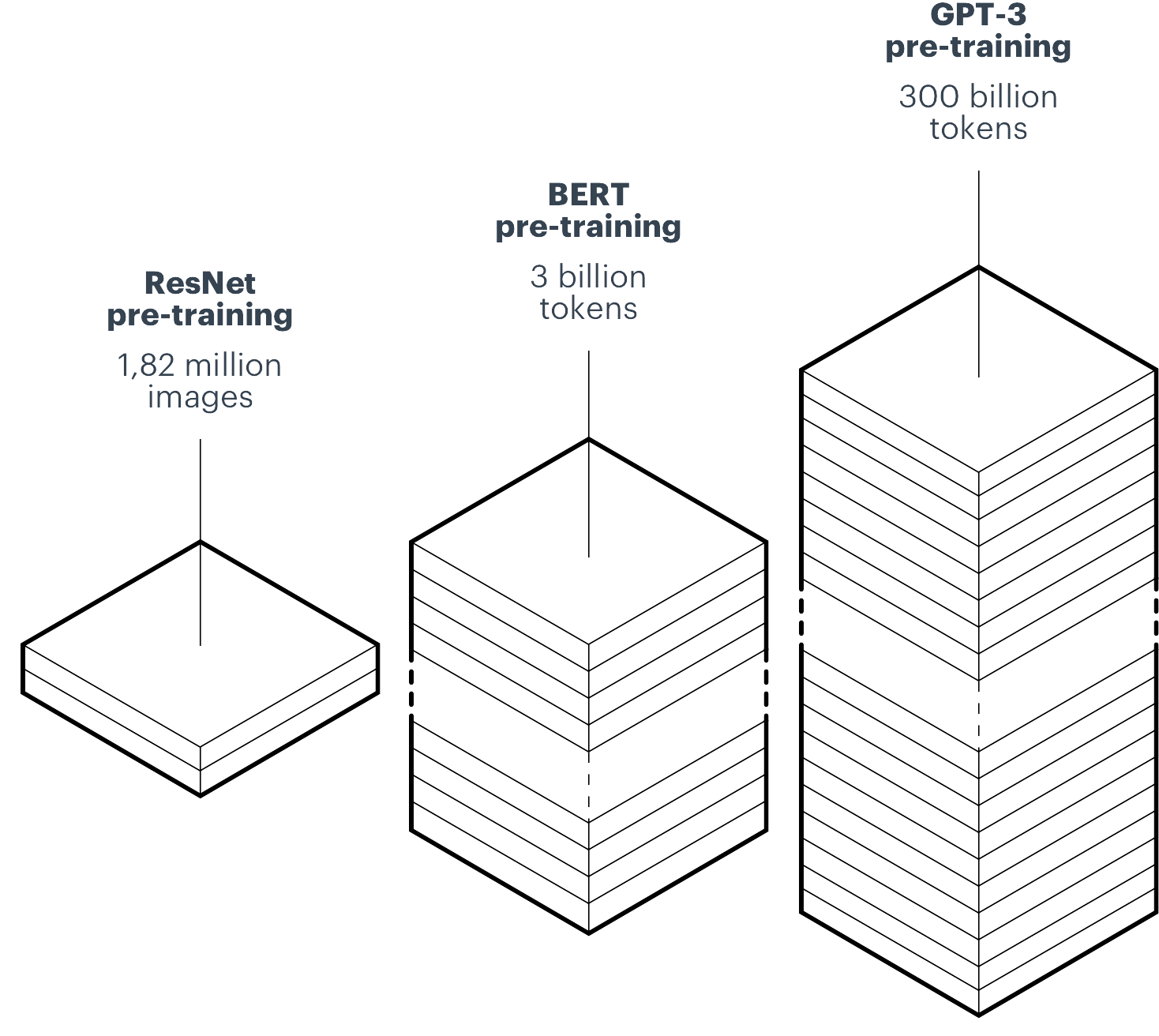
The idea behind foundation model pre-training is to extract knowledge and create robust representations that can be re-used in different tasks. However, it requires models with a great number of parameters. The ResNet model (image classification) has 11 million parameters, BERT-base has 110 million parameters, and GPT-3 as many as 135 billion trainable parameters. Also, the pre-training procedure requires large-scale datasets: ImageNet - 1.82 million images and 1000 classes; BooksCorpus - 800 million and English Wikipedia - 2,5 billion words (BERT pre-training), and the enormous set of 300 billion words sampled from five different datasets (Common Crawl, Web Text2, Books1, Books2, Wikipedia) used to train GPT-3. All of this translates into a considerable amount of computational power needed to pre-train models. We end up with massive foundation models which only a few of the biggest research labs can contribute to and not everyone can use in real-life applications.
With the rise of foundation models in NLP and vision, a question arises about the future of our research area: recommender systems. Can we expect to find a single representation or model serving different purposes here? In fact, we perceive recommendations as a part of a broader area which we call behavioral modeling. Behavioral modeling can be thought of an umbrella term for many interconnected tasks like recommendations, churn prediction, propensity scoring, link prediction in graphs, and many others. All of these tasks entail the automated study of human decision-making. Taking into consideration the success of universal representations in NLP and vision, together with the complexity of behavioral modeling, we suspect that a universal multi-purpose model is particularly fitted for this domain. The areas of behavioral modeling are extremely numerous, thus the creation of multiple, large and varied per-task models is infeasible both from a business and environmental perspective.
Towards a universal behavioral model
A universal behavioral model should fulfill the base criteria of the big multimodal foundational models:
- It should be able to process multiple modalities, such as text, image and possibly various interaction types, especially important for behavioral modeling;
- It should be applicable to many tasks (with separate training or fine-tuning).
With real-life use cases in mind, we could go even further to address the known shortcomings of the big foundational models. Thus, our universal behavioral model could:
- Be small: only a few hundred/thousand parameters or not be a neural network at all;
- Be fast: in connection with the small size, it could quickly train and allow for semi-instant inference;
- Not require huge amounts of data to produce meaningful representations;
- It could even be purely unsupervised, focusing only on producing universally useful features, which could then be fed to simple and efficient downstream models for great results.
Thus, we have set our goal as follows: to create a universal behavioral model, which could serve all the above purposes.
Cleora & EMDE as a universal behavioral model
A natural setting for the representation of human decisions in time and space are graphs: sets of interconnected nodes. Nodes can represent various entities, such as humans in a social network, or items and customers in a store. The edges represent different relations between them, such as friendship or the fact that a person bought an item in the past.

Thus, graph modeling is of top importance in behavioral modeling. We approached this problem with Cleora – our node embedder. The algorithm is based on the iterative multiplication of the Markov transition matrix and the embedding matrix. As a result, nodes with similar neighborhoods have similar embeddings. Node representations created this way are task-independent, so can be applied in many different solutions. What is more, the algorithm is fast and scalable, which makes it applicable to large graphs. You can learn more about Cleora here: Cleora AI framework for ultra-fast embeddings in large graphs.
Behavioral modeling requires more complex representations that go beyond relational information embedded in graphs. For example in recommendations, in order to observe some traits in user behavior, we need to aggregate the information about user past purchases, but also create rich representations of objects that the user has viewed. To do so we must incorporate information from different modalities such as image or text. Our second model, the Efficient Manifold Density Estimator (EMDE) addresses this need. EMDE uses a density-aware manifold partitioning method in order to create meaningful manifold regions. Each region holds samples which are similar according to the distance metric expressed within the embedding space which spans the manifold (e.g. produced by Cleora). The resulting region assignment vectors (sketches) can be generated from different types of input and concatenated to serve as an input to a model that will be trained for a given task.
EMDE can be thought of as an unsupervised super-embedder which translates and compresses all modality-specific embeddings to the same kind of representation – the sketch. The sketches are sparse by design. Moreover, they allow for easy aggregation of multiple events/items/behaviors in one sketch. Such aggregate sketches can be thought of as histograms representing the occurrence rate of various events.
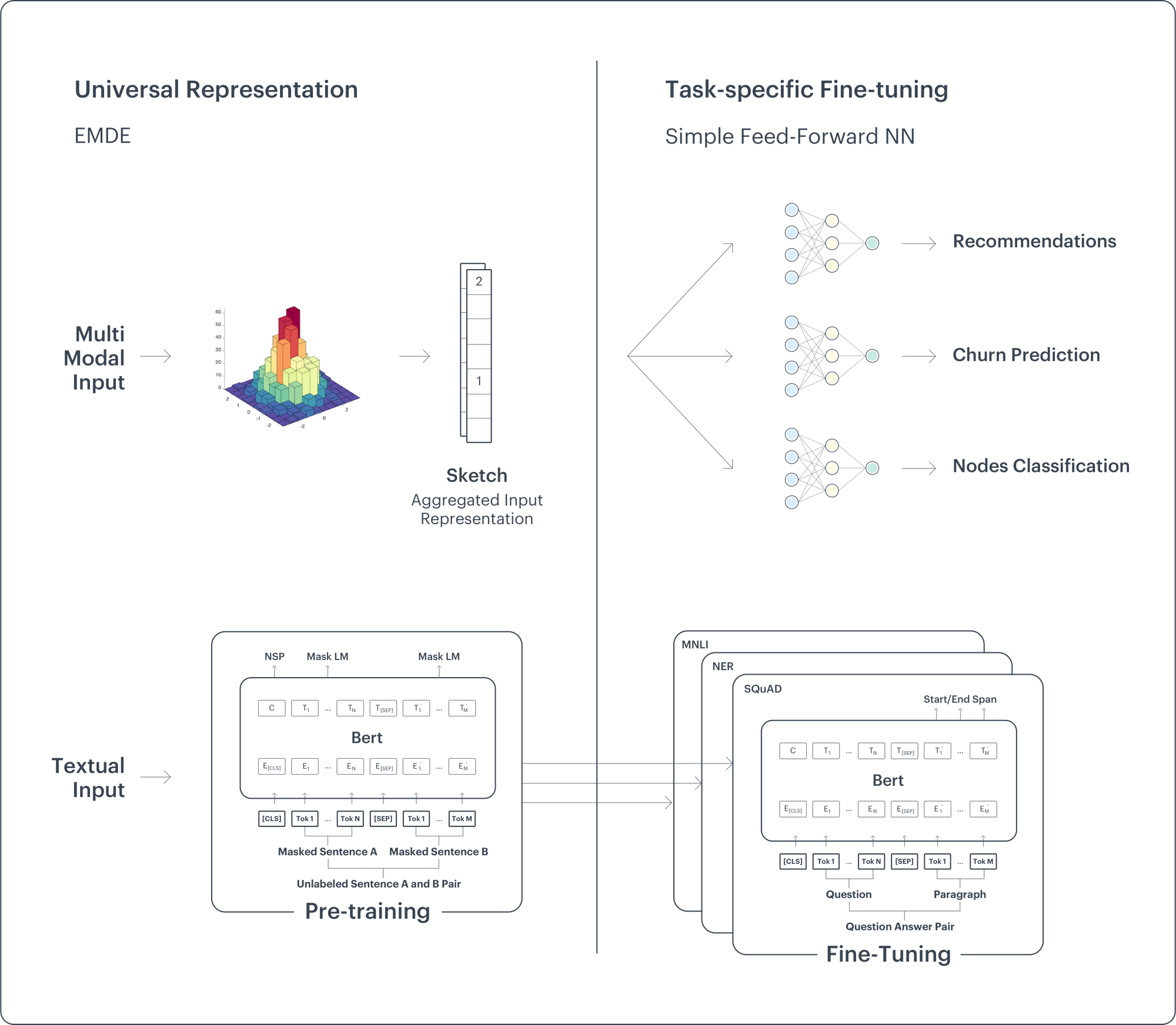
In the next sections, we show that these algorithms create universally useful representations. They can be re-used in numerous tasks with extremely simple downstream models to achieve state-of-the-art or near state-of-the-art results.
Universal behavioral modeling framework
To verify the usefulness of our approach, we participated in several large-scale competitions which spanned a set of seemingly distant problem areas. Each area had its own champions, models which are designed for and known to excel in their respective areas. We, however, approached the competitions with a universally similar setting:
- Whenever needed, we produced graph embeddings for input data with our graph embedder, Cleora. Graph embeddings are a fairly versatile approach as many input modalities can be embedded this way: transactional data, social network data, textual data, and any other data type which involves sets of linked entities.
- With EMDE, we produced multimodal input features based on local similarity of input embeddings. Sketches generated by EMDE are especially amenable to aggregation, so representing sets of behaviors (e.g. multiple purchases or site visits across time) proved very convenient.
- We applied an extremely simple model to ingest EMDE features and produce the target response. We usually used shallow feed-forward neural networks of 3-4 layers.
- Optional additional numeric features were also submitted to the model (not produced by other machine learning models).
We took part in the following competitions:
- KDD Cup 2021
- Twitter RecSys Challenge 2021
- WSDM Booking.com Challenge 2021
- SIGIR Rakuten Challenge 2020
With the aim to test and validate our solution robustness and its ability to perform in various tasks. Our hardware dedicated to competition models was average at best, and our models were not extensively fine-tuned. For each competition, we used a pretty standard set of parameters which usually worked well in the past. We let go of the competitive urge to fight for every decimal point in the final result score.
The Competitions

WSDM Booking.com Challenge
Task: Sequential Recommendation of Next Travel Destination
Our Result: 2nd Place
Our Solution: Modeling Multi-Destination Trips with Sketch-Based Model
Recurrent Networks were the top choice in this competition: clearly the notion of city ordering was deemed crucial by the participants. All top solutions included RNNs, additionally the top entry by NVIDIA included a Transformer. This particular solution was very elaborate and task-specific.
The striking result in this competition was that EMDE does not naturally represent ordering in sequences. It can model ordering only in a very simple way by weighting more recent items or using an extra sketch of recent items. Therefore, we did not have high expectations from this competition initially, as we also assumed that the RNN-based solutions might have an edge due to the importance of sequentiality.
However, the success of EMDE seems to support our previous findings regarding session-based recommendations (An efficient manifold density estimator for all recommendation systems Section 4.1.1): the sequential aspect seems to be outweighed by the accuracy with which EMDE represents the probability density of user preference space.

KDD Cup: Open Graph Benchmark Large-Scale Challenge
Task: Subject area prediction of papers in large-scale academic graph. Classify nodes in a large graph with many types of nodes and relations present.
Our Result: 3rd Place
Our Solution: Node Classification in Massive Heterogeneous Graphs
Top performers:
- Baidu: UniMP architecture combined with the best baseline solution — Relational Graph Attention Networks
- DeepMind: Message Passing Neural Networks with self-supervised learning technique
Graph Neural Networks were predominant in the competition. However, they required the additional effort to make the models scalable to large graphs. For example, the DeepMind team used different subsampling procedures to create smaller graph patches and facilitate model performance. Cleora and EMDE architectures are scalable by design, so can be used on large graphs without employing additional methods. Worth noticing is that our model inference takes 7 minutes (1x Tesla V100 16 GB GPU and Intel Xeon CPU ES-2690 v4 @ 2.60 GHz), while DeepMind’s model inference takes 12 hours on 4x NVIDIA V100 16GB GPU and 1x Intel Xeon Gold 6148 20-core CPU.
This task demonstrates that with the use of Cleora and EMDE we could implicitly achieve a similar technique to the competitors – the label/feature propagation in a graph neural network. We achieved this by simply initializing Cleora vectors to one-hot encoded vectors, with the value 1 denoting the current label.

RecSys Twitter Challenge
Task: Near Real-Time Recommendation of Tweets. Predict whether a given user will like a tweet, given tweet text, features of tweet author and recipient, tweet hashtags, and many other features.
Our Result: 2nd Place
Our Solution: Twitter User Engagement Prediction with a Fast Neural Model
Top performers:
- NVIDIA: extensive feature engineering with a simple XGBoost model. Many features are created and tested. Specific simple, non-neural encoding methods such as the Target Encoding technique were discovered by them to be effective in feature representation.
- Layer6 – Deep Language Models (Transformers) used for elaborate processing of tweet text, combined with many hand-crafted models.
Of all the competitions, this one had one competitor (NVIDIA) which was very close to EMDE in terms of paradigms and model structure. Both NVIDIA’s solution and our EMDE-based model involved elaborate feature engineering combined with a simple model. As usual, EMDE moved the heavy-lifting part of the computation process into the feature creation.

SIGIR Rakuten Challenge
Task: Cross-Modal Retrieval. Given the titles and descriptions of products, predict their matching images.
Our Result: 1st Place
Our Solution: Efficient Manifold Density Estimator for Cross-Modal Retrieval
Top performers:
- Purdue University and Rakuten: Deep Multimodal Fusion with Highway Networks and tensor fusion
- Ping An Technology: Deep Multimodal Fusion at multiple levels with various approaches, such as attention and shallow network classifiers
In this competition EMDE allowed us to reconciliate non-matching modalities (text and images) with the universal sketch representation. With both title/description and image embeddings encoded into sketches, we were able to easily train a simple feed-forward network comparing the representations (effectively comparing two histogram-like structures). This allowed to beat elaborate multimodal neural models.
Why does EMDE lead to a universal behavioral model?
Why does this combination of EMDE with a simple neural network work so well compared to many very complex neural architectures? The answer is yet to be studied to know for sure. However, we have come up with a few ideas:
- EMDE makes training easier. A large part of the work each model needs to perform lies in inferring the similarity relations encoded in input embeddings. These relations are encoded in a unique way for each embedding method and might be hard to learn. However, EMDE translates local similarity of inputs into a clear and easy-to-process representation, which liquidates this initial hurdle.
EMDE is a very good probability density estimator (see Section 4.2 in An efficient manifold density estimator for all recommendation systems). Probability density estimation may be a fundamental problem in many areas, especially when multiple events are encoded across time and/or space. Think about heat maps of travel routes, which represent the frequency with which certain places are visited by travelers.

This problem directly corresponds to user preference spaces in a shopping scenario, among many others. Both geographic location data understood as a 2D space and multidimensional behavioral data can be modeled in terms of complex probability densities with many peaks and valleys. These landscapes represent the problem of varied occurrence rates of events or intensity of interests. However, direct density estimation is not performed by any other recommendation model that we know of.