
Why We Need Inhuman AI

Self-driving cars do not yet roam the streets. AI has yet to wait to independently generate a computer game or a larger piece of software, and chatbot assistants are only carefully deployed with human assistants as backup. We continuously wonder how much longer it will take until AI reaches human skill level in these tasks - or, when does AI become "truly" intelligent. This question often poses an implicit assumption that human intelligence is the perfect design to which AI should aspire to. However, we need to remember that at this very moment various forms of AI surround us which overshadow human abilities in their respective areas of operation.
In this article I share some intuitive arguments and examples of limitations of human cognition, compared to the abilities of current digital systems. I aim to show that while human performance should be pursued as a gold standard in some tasks, in other tasks even human experts can be easily beaten by an inhuman AI. This is because we have been subject to evolution – a purposeful process which honed a selected set of skills to handle a specific set of challenges posed by our environment. However, the modern world of large and often abstract data streams creates previously unknown challenges. To solve them, we need a different kind of intelligence than our own. Here we arrive at the term “inhuman AI", which raises rather negative connotations. It is usually associated with catastrophic visions of powerful, evil AI hurting humanity. However, in practice we already exploit the inhuman side of AI to our great advantage.
Where humans underperform
Historically, we tended to evaluate certain tasks as easy because most healthy people can perform them without much conscious effort. This applies to for example walking, language understanding and image analysis, such as segmenting objects or assessing depth and distance relations in a picture. Other tasks used to be thought of as hard because only selected (most talented or hard working) people could perform them. In the early days of AI this notion applied to e.g., games such as chess and go. Obviously AI has beaten human world champions in both these games (DeepBlue and AlphaGo/AlphaZero), as well as in online RTS gaming (OpenAI’s Dota player system) and poker (CMU’s Texas Hold’Em player system), among others. At the same time, natural language processing and vision systems are still far from human performance, and brittle in terms of generalization abilities.
The mind is a system of organs of computation, designed by natural selection to solve the kinds of problems our ancestors faced in their foraging way of life, in particular, understanding and outmaneuvering objects, animals, plants, and other people.
– Steven Pinker, "How the Mind Works”
In fact, the most “basic” human or animal abilities such as walking on two or four legs or small motor skills of the hand are characterized by considerable computational complexity. They are so hard that no artificial system can match them – yet humans can perform them (almost) subconsciously and effortlessly. This is an effect of evolution working tirelessly for millions of years to refine these abilities to perfection. In comparison, higher cognitive abilities such as complex logical reasoning and abstract thinking are an early invention in terms of evolutionary time scales – they started to develop only around 100,000 years ago. Their early stage of development manifests in the way high cognitive skills seem to be harder and require far more deliberation and conscious effort than for example walking. Interestingly, “primitive” and “advanced” human neural skills appear to have conflicting aspects. High cognitive functions have developed on top of more primitive mental structures, so the resulting performance is not entirely optimal due to previous "design choices". Possibly, this is connected to multiple cognitive biases of the human mind which lead us to making wrong, irrational decisions [1,2,3]. Examples of such biases are the confirmation bias (the tendency to interpret and remember information in a way that confirms our beliefs, views, or expectations), or the availability bias (the tendency to erroneously assign greater importance to events only because they were seen recently), among many others. One of the explanations for the existence of cognitive biases is that the human brain simply lacks the power to process such complex situations and must resort to shortcuts or severe simplifications [4]. Unfortunately, as humans we are not aware of the biases and are usually convinced of acting rationally and objectively.
Thus, it is evident that in the past we were many times wrong in our assessment of “objective” task difficulty, as well as our own inherent cognitive limitations.
Games – a need for more memory
It is true that chess and go require complex strategic thinking. However, the example of the most successful AI game playing algorithms shows us that a vital element is the ability to analyze game trees – that is, the ability to look deeply into the future. The game tree is a representation of combinations of future move sequences. Consider a chess board during play:

From here, multiple moves are possible – for example, we can move the Black Queen to A3, B3, or D4. Each of our moves can either deteriorate or enhance our position on the board and has its place within a larger strategic scheme. However, we must also consider what the opponent will do after our move. Each possible opponent reaction opens up multiple new movement opportunities. The resulting game tree of all our possible moves and all opponent possible moves grows to a huge size:
In order to understand the volumes of data we are dealing with, let’s consider some statistical properties of chess and Go, such as the branching factor, average game length, and game tree complexity. The branching factor expresses the average number of legal moves available to the player each turn. Chess has a branching factor of 35 and Go – 250. A single chess game ends in 70 moves on average, while Go - in 150. What interests us the most is game-tree complexity, which denotes the number of leaf nodes in a full game tree. For chess this equals 10^123 and for Go – 10^360. These numbers are actually hard to comprehend. The number of atoms in the universe is “just” 10^87.
For an AI system, the amount of available memory and compute is enough to quickly produce and store game trees of large size (usually not full trees, but still large), impossible to remember for humans. Modern game-playing AI systems can selectively “look through” many possible game strategies in order to reason about best possible moves and explicitly decide which paths are viable of consideration, and which should be dropped. This allows for selecting the best optimal strategy in objective terms, even if it is not the most obvious one. In fact, a special AI-inspired term has been coined to denote weird, unexpected chess moves – they are known as "computer moves”. This refers to how AI-generated moves often look confusing or even senseless at first – yet their utility is revealed much later in the game.
As a result, human masters have consistently been losing chess plays to AI within last 15 years, and it is universally agreed that no human can possibly win with a high-grade AI chess player.
Abstract numeric problems
As noted before, humans are evolutionarily primed to swiftly process language and vision signals. We are way worse at processing symbolic data, particularly numbers. However, many problems nowadays are expressed in an inherently numeric format - imagine signals from sensors in factory production lines, financial data, or signals from medical devices recording various aspects of the heart rate, oxygen saturation, perspiration rate, and many others [5] in real time. They form sequences of raw numbers, in which patterns need to be spotted in order to derive any useful information. An extremely important ability is for example the skill to spot which numeric datapoints are closer ("more similar") to another datapoints. This way we can detect similar cases of illness or factory malfunction to the ones which happened in the past.
Let’s see how well we as humans can perform pattern spotting in raw numeric data. Consider a bunch of point coordinates in a 2D space – each row denotes a pair of X and Y coordinates of a single point. Think what popular shape these coordinates could represent:
[-6.13, 6.09],
[ 5.57, -10.06],
[ 0.005, -4.71],
[ 2.18, 7.24],
[ 5.99, -1.14],
[ 4.27, -3.59],
[ 6.36, 1.19],
[-9.16, 7.92],
[-4.76, 6.99],
[-9.14, -3.50],
[-6.27, 5.98],
[1.94, -11.00],
[ 6.22, 2.31],
[ 11.85, 5.32],
[ 1.27, -4.81],
[ 0.39, -11.02],
[-6.15, 6.08],
[-8.49, -5.24],
[ 5.85, -1.48],
[ 11.69, -3.71],
[ 4.08, 13.22],
[ 1.43, 7.53],
[ 2.69, -10.91],
[ 11.92, 5.12],
[ 11.01, 7.18],
[ 3.96, -3.84],
[ 1.83, -4.74],
[ 6.31, 0.19],
[ 11.85, 5.32],
[ 4.51, -3.39],
[-6.39, 5.88],
[ 5.31, 12.67],
[-9.27, -2.99],
[ 2.64, -10.92],
[ 1.28, 7.58],
[ 2.08, -10.99],
[ 12.58, 0.15],
[ 0.84, -4.81],
[ 8.34, -8.32]
Judging by the numbers alone (without an attempt at plotting the datapoints), it is virtually impossible to say which shape they form, or or what are the distances of points along the line which is drawn.
Only after plotting does a pattern start to emerge:
And gets more pronounced with more points:
This is where the area of data visualization takes its roots: it is far, far easier to observe a tendency in visualized data, than in pure numeric form. If we could have said that the pattern is a spiral judging from raw numbers alone, the large data visualization business with companies such as Tableau, Grafana or Dataiku would never have been born.
Now, let’s take a look at an algorithm called tSNE [6], a dimensionality reduction method. This algorithm can “understand” data by ingesting a pure numeric form and based on this alone, it can reason about the “true” proximity of points on complex nonlinear manifolds very accurately. The spiral example is no big deal for tSNE, which correctly models the distance problem on the "Swiss roll" shape (marked with the solid line):
Note that the 2D example we have analyzed so far is in fact an extremely easy case, since most numeric signals would have hundreds or thousands of dimensions. Now, it is not even possible to visualize a hundred/thousand-dimensional space for human inspection, or even imagine such a space. Here we must rely on machines fully. In fact, tSNE and many other machine learning are designed to handle thousand-dimensional spaces.
Enter Big Data
Our final example will refer to big data – massive datasets composed of billions of data points. Many vital areas of human life rely on big data processing:
- Fuel and stock optimization tools for the transportation industry,
- Live road mapping and route planning for both human drivers and autonomous vehicles,
- Traffic modeling, prediction of traffic jams and accidents,
- Meteorology: weather prediction, disaster prediction, study of global warming from massive amounts of signals from satellites and sensors,
- User demand prediction in e-commerce, online music and streaming services,
- Monitoring health conditions through data from wearables,
- Discovering consumer shopping habits derived from millions of users of sites such as Amazon,
- …. and many more.
From its very definition, big data modeling aims to discover insights hidden in enormous amounts of data. In order to detect patterns, oftentimes it is necessary to perceive a dataset as a whole. Small chunks of data often do not disclose any meaningful pattern and can also contain false patterns which disappear on a large scale. Consider a patch of an LCD screen and a full screen:
While using displays and screens, we need to keep a certain distance to perceive the whole picture. Seeing only tiny pieces of data (such as a few pixels), it is virtually impossible to say what the screen displays. It’s even worse with real numeric big data, because we have no prior intuitions about what certain signals could mean.
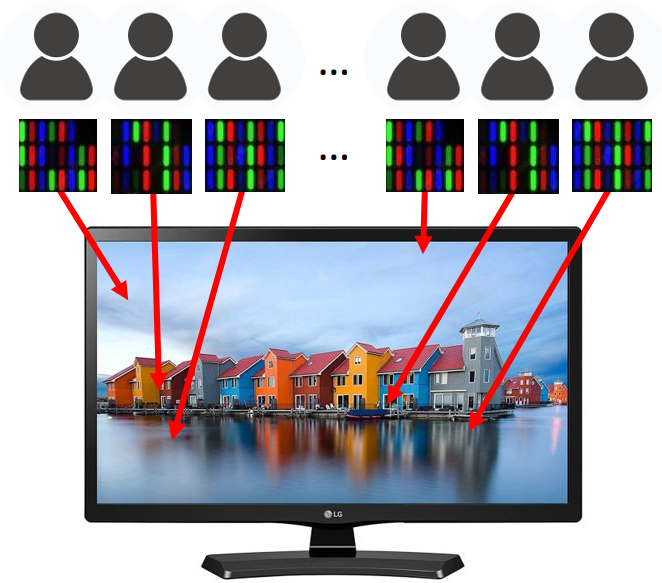
Imagine an army of agents with limited capabilities of memory and processing power, able to look for local patterns only. This army is by no means guaranteed to find a legitimate global pattern. The whole dataset must be processed by a powerful agent aware of all its constituent parts. (In fact, there is a branch of science dedicated to studying whether global tasks are solvable by systems of limited agents, called Global To Local Theory.)
Even if we tried to experimentally verify the hypothesis that our army of humans can discover global patterns in big data, we immediately run into practical problems. Due to slow and small working and long-term memory, as well as slow process of data transmission (humans need to read or hear information, which is painfully slow compared to digital data transmission), it is impossible to expect that human agents can process billions of data events in reasonable time and with reasonable effort.
Summary
As we can see, a lot of vital applications of AI rely on fundamentally inhuman skills. However, the inhumanity of AI can sound like a negative trait, or even threatening when perceived from an ethical point of view. Yet it is evident that this type of computer intelligence is needed to patch up some inherent flaws of our cognition. Inhuman AI pushes the potential of our civilization far beyond our evolutionary design. With amazing achievements such as GPT-3, DALL-E, Imagen, and others trying to catch up with human skills, let’s remember that we have been already beaten many times before, yet at different tasks – and to our advantage.
Bibliography
[1] Korteling, J. E., Brouwer, A. M., and Toet, A. (2018a). A neural network framework for cognitive bias. Front. Psychol. 9, 1561. doi:10.3389/fpsyg.2018.01561
[2] Korteling, J. E., van de Boer-Visschedijk, G. C., Boswinkel, R. A., and Boonekamp, R. C. (2018b). Effecten van de inzet van Non-Human Intelligent Collaborators op Opleiding and Training [V1719]. Report TNO 2018 R11654. Soesterberg: TNO defense safety and security, Soesterberg, Netherlands: TNO, Soesterberg.
[3] Moravec, H. (1988). Mind children. Cambridge, MA, United States: Harvard University Press.
[4] Friedrich, James (1993), "Primary error detection and minimization (PEDMIN) strategies in social cognition: a reinterpretation of confirmation bias phenomena", Psychological Review, 100 (2): 298–319, doi:10.1037/0033-295X.100.2.298, ISSN 0033-295X, PMID 8483985
[5] Annica Kristoffersson and Maria Linden (2020) “A Systematic Review on the Use of Wearable Body Sensors for Health Monitoring: A Qualitative Synthesis” https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7085653/
[6] L.J.P. van der Maaten and G.E. Hinton. Visualizing High-Dimensional Data Using t-SNE. Journal of Machine Learning Research 9(Nov):2579–2605, 2008.