
Project BaseModel

In this article we introduce BaseModel, a tool which makes the most of event data reflecting user behavior. Working with clients in many different industries, we have observed that large company data is often underutilized. Here we will discuss where our research on BaseModel arises from, how we meet strict requirements connected with big data processing, and how it can help data scientists make their work less time-consuming and more oriented towards the creative part of the process. We introduce some important concepts connected with AI-driven analyses of interactions hidden in event data and how to use it to better understand your customers and services.

There are several key stages of work needed to create a viable AI model. The most obvious one is creating and training ML algorithms to solve given tasks. However, the effort in preparing input data representations is equally (if not more) important. Having some relevant data in our domain of interest, we must consider which information is important and how to represent it numerically. These representations should accurately encode the relevant information, usually in a compressed form, and be in line with the requirements of our selected AI algorithm. If we want to estimate real estate prices, we realize that we need to know the total square footage, number of rooms, and so on, but we could possibly also use the average temperature in a given region. And what if we want to add information about the quality of the neighborhood – how to quantify and represent it numerically? Bear in mind, that real estate pricing is the “hello world” of machine learning and with more elaborate use-cases things become more and more complex. For example, modeling human behavior is based on multiple factors which are entangled with our psychology and it is hard to even find potential features. A lot of research and effort goes into building better tools to understand and utilize data depending on its type, modality, but also creating a model equipped with a “basic knowledge” that can be used in different domains and downstream tasks.
Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.
~ Andrew Ng
Where we’re at? Image, text, and foundation models
A particularly hot topic in AI research are foundation models. They are trained on a vast amounts of data of a general nature, not tailored to some specific task or one specific domain, often in a self-supervised manner. They store general knowledge that can be further used in various downstream tasks. Some of them require model fine-tuning – additional training for a given task or on domain specific data. For example, we can fine-tune a language model to classify texts into categories. Other tasks are learned in a zero-shot manner, so the model is capable of solving a given task without any fine-tuning only by providing the needed prompt to the model. One example of such ability is DALLE’s image-to-image translation. The model can present the same object in different styles, for example creating a picture of a cat based on a sketch of a cat.

Foundation models mark a shift in how we are approaching AI. A lot of focus is put into this research, with initiatives such as Stanford's Center for Research on Foundation Models or some recent catchy examples as ChatGPT or DALLE. In 2021 the Workshop on Foundation Models was held, where it was stated that in the last 2 years all state-of-the-art models in text and vision leverage foundation models.
Self-supervised learning is an important training technique for building foundation models. It extracts information encoded in data intrinsically, omitting any data labeling effort. It predicts the hidden aspects of data based on observable context. Hence, we can utilize large quantities of data of a general nature, without the additional effort of high-quality task-specific data annotation. There is a famous analogy coined by Yann LeCun:
If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL)
In reinforcement learning a model need many samples to learn expected behavior and supervised learning requires human intervention in creating training data, one sample usually carries one piece of information e.g., a text paragraph is mapped to a single category. However, in self-supervised learning from one text paragraph we can extract much more information – each word with its context can serve as a separate training example. For these reasons, for Yann LeCun, self-supervised learning is the future of AI.
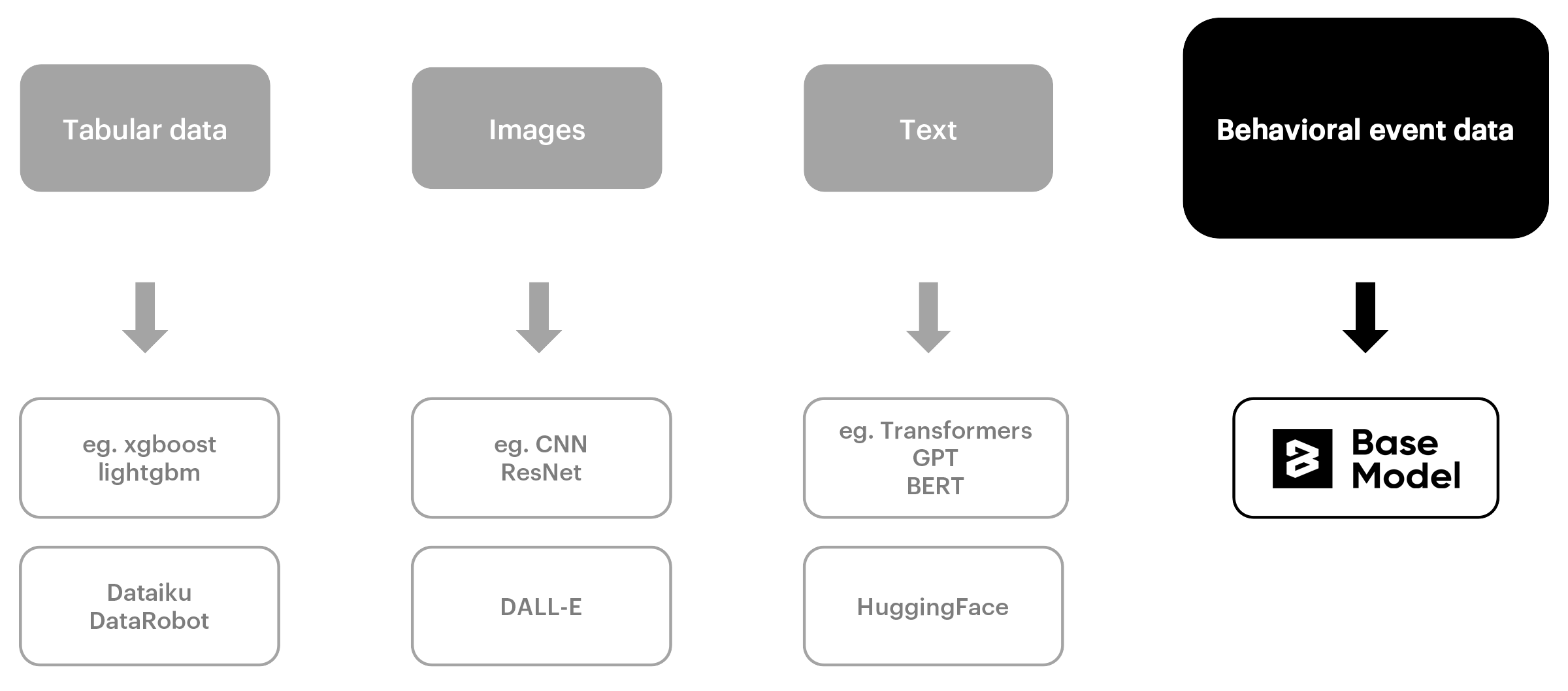
However, natural language and image are not the main data formats in which companies store information most valuable for their business. The majority are big, interconnected event data, that stores valuable insights, and are often underutilized. This important field was left behind when it comes to using the power of self-supervised learning, research on data representation and foundation models. We lack general-purpose tools to represent entities in this data and models we could build upon. This lack is alarming as many fields can benefit from such solutions fitted to production environment, but also because some important part connected with human activity was left out. An effort was made to imitate our language and visual skills, however, the area of human behavioral patterns and preferences seems to be left behind.
Enter project BaseModel.
Behavioral data
Behavioral event data are records of human interaction with services or products and can be found in many different domains such as retail, finance, e-commerce, automotive, telecom. Some examples are products bought by users, card transactions, what users follow, what ads they click, etc. With this kind of data, we can harness artificial intelligence capabilities for our needs.

We develop BaseModel to easily operate on event data. It allows you to create representations of users, products, and services based on their interactions, in self-supervised manner, and use them to train a foundation model. It can serve in many downstream tasks – predicting future interactions, segmentation, recommendation, user engagement prediction - at this point sky is the limit. For businesses, it means greater knowledge about their clients, but also about their products and services. Products can be seen through the lens of user interactions and provide a better understanding of users and their engagement. It enables defining business key components in a way that is specific for the particular case. Finally, we can create proof-of-concept solutions in considerably less time and easily test new ways to enhance our product, or gain additional insights about our customers.

BaseModel
The conceptual core of BaseModel are universal behavioral profiles. They compress user behavior into actionable predictive representations. What does it mean in practice? It significantly decreases development time in ML projects, as there is no need to manually create features, separately for each model. A common but sub-par industry practice is that features which need to be aggregated to represent a certain entity, e. g. events generated by a single customer are usually represented with averaged embedding vectors representing products they bought. BaseModel universal behavioral profiles come with a special procedure of aggregation, which is much better than averaging – it keeps the individual identities of aggregated entities in place, allowing for precise reconstruction of each individual item from the aggregate representation. Hand-crafted features can also be added to the behavioral profiles with simple concatenation.
As BaseModel needs to be effectively applied to big data problems, its scalability is another very important aspect. We put an extra effort into making it fast and lightweight, well adapted to the demanding production environment. When we look at corresponding solutions in text and image domain, they require significant resources and aren’t yet fully fitted for real-time production settings. Not to leave you with unfounded claims, let’s proceed to the technical details of BaseModel.
Graphs everywhere
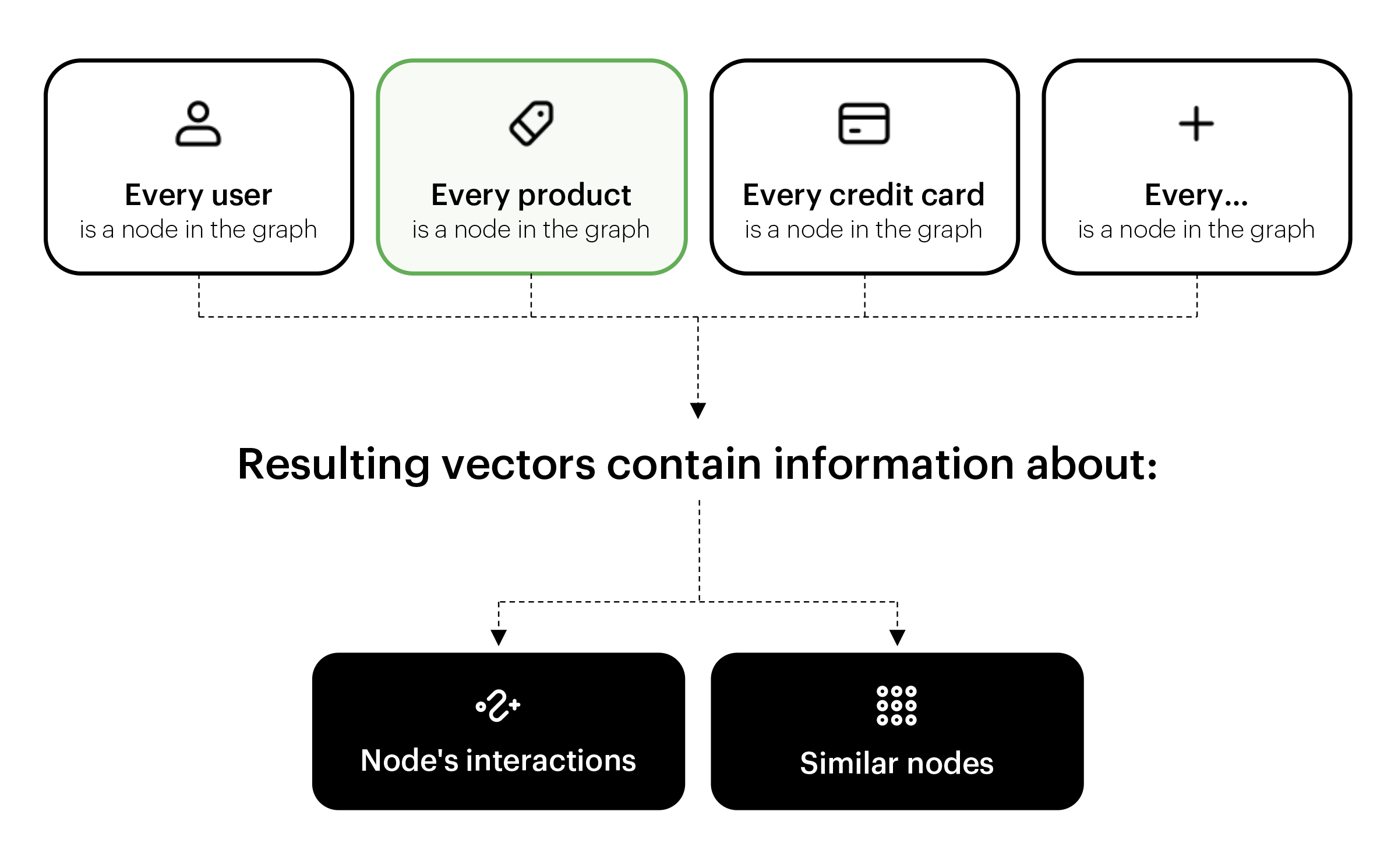
In the first step, BaseModel detects graphs and hypergraphs in user interactions. A graph is a data structure where nodes represent entities, and edges represent relations between entities. In a hypergraph an edge can join more than two nodes.

Graphs are very potent when it comes to representing real-world events and, as such, are particularly well fitted to user interaction data. Nodes can represent users, products, services, transactions or even product categories, prices, basically anything from our data that can be interpreted as an entity. Edges can represent relations between any two or more entities: user bought product, user followed user, user spent given amount of money, the product was bought together with other product, etc. For that reason, the first stage of the BaseModel pipeline is to look for graphs in event data and convert them into vectors – graph embeddings. We use our proprietary algorithm, Cleora, that transforms raw data into ML-interpretable vectors that are based on graph data structure and contain information about node’s interactions and similarity. A detailed description of the algorithm can be found here.
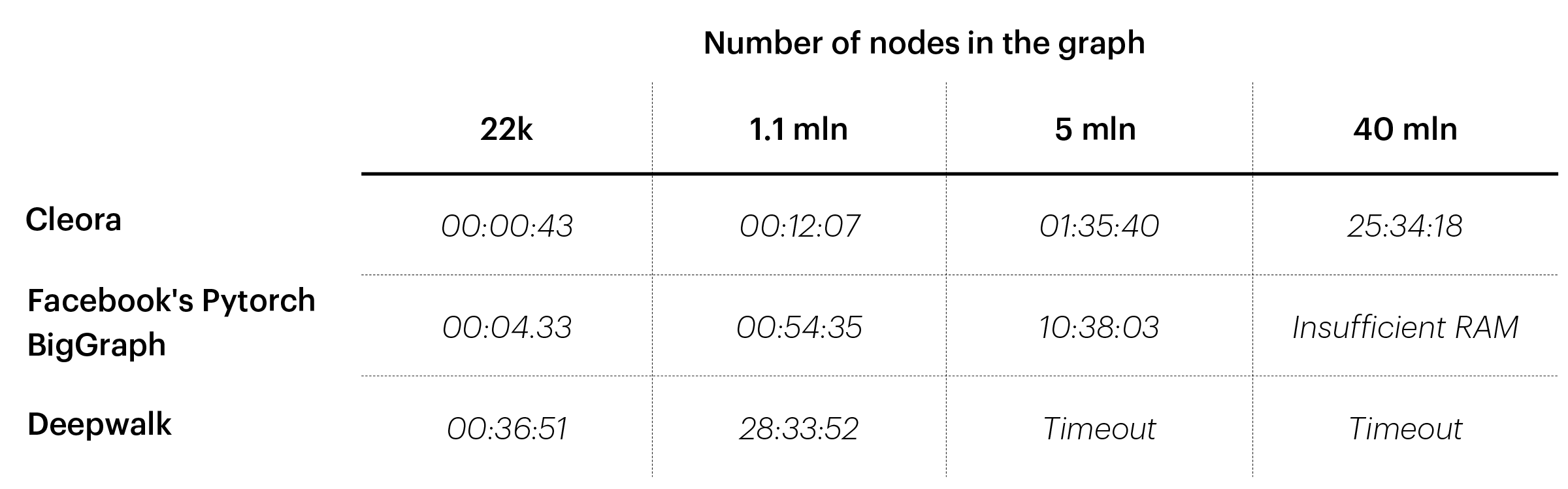
Making Cleora ultra-fast and scalable was of great importance to us as we deal with large amounts of data in industries like retail, banking, or telco. Graph Neural Networks, which are the most popular graph embedding approach, require many GPUs and tremendous engineering effort to scale with huge event data graphs. Cleora can work on a single GPU and takes a few minutes to process graphs with as many as 1 million nodes.
Universal Behavioral Profiles
Once we have vectors which encode information about entities in our data, we can use them to create universal behavioral profiles. Our EMDE algorithm (for details see our blog post) aggregates information from multiple events into a single vector for a given entity. In a basic example, we can imagine multiple products bought by one user being aggregated into vector representation of this user. An important feature that distinguishes EMDE algorithm from other methods of vector aggregation, such as averaging, is preserving information from each vector. In the example with product purchases, it would mean that we don't create an average product, but we keep the notion of product similarities and maintain each product characteristic.
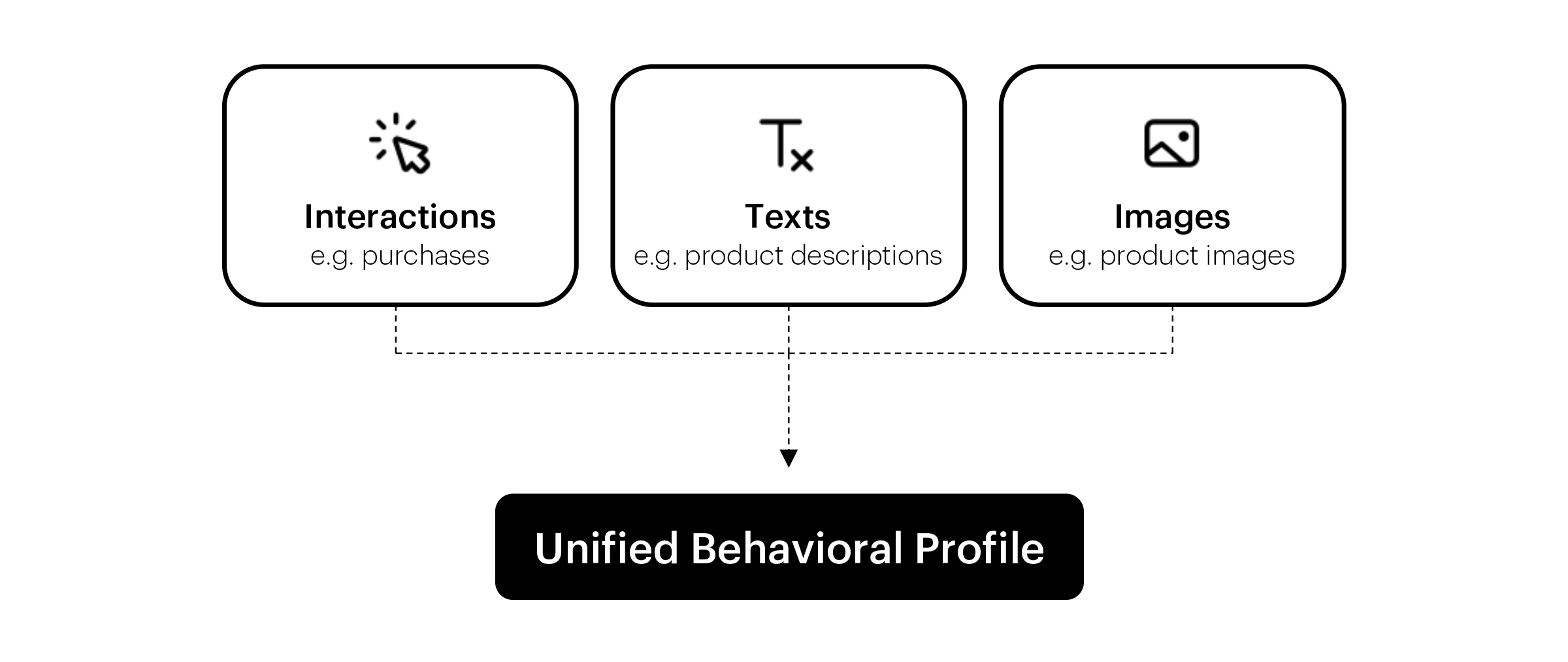
We can combine information from multiple sources and modalities to create a robust representation of a given entity. We can create a behavioral profile of any entity in accordance with our needs and data specifications, including not only users but also products, stores, employees, etc. For each entity, we can combine multiple event types encoded with Cleora, but also additional data sources like texts or images. We can also enrich these representations with some static features that don’t require graph-based modeling such as user age, or product attributes. Resulting EMDE vectors are fixed-size structures independent of the input embeddings size. What is important, behavioral profiles can be maintained in real time, so we can provide up-to-date representations for further predictions.
Predictions – where it all comes together
Now we can connect all introduced concepts to uncover the true power of BaseModel. Universal behavioral profiles can be used to train a neural network to predict future interactions. To do so we can utilize a self-supervised training technique by predicting future continuation of the data based on available history.
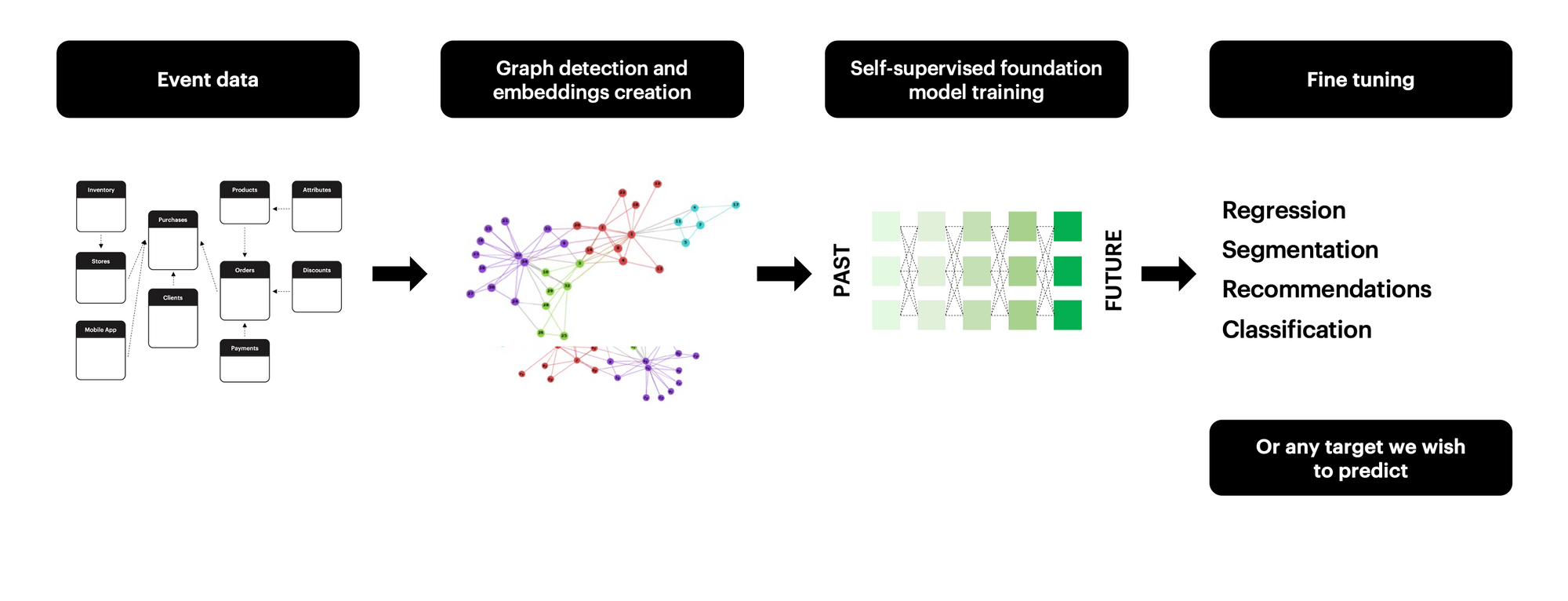
We create a behavioral profile based on events before some arbitrary time split and predict the behavioral profile after the time split. This way we end up with a foundation model encoding knowledge about user behavior and interaction patterns. What distinguishes this solution is the size of the model and training time. In text or image processing, the whole effort goes into making models better, but not smaller or faster, so model size and training time are what make the improvement in this area. In behavioral data processing, we often deal with very strict time constraints and we need to approach hardware requirements realistically. As we put stress on creating robust data representations – universal behavioral profiles, we can lighten the model training part. Thanks to our research in efficient high-dimensional manifold density estimation, we can use state of the art feed-forward networks with just a few layers to train very robust conditional models. This is a great improvement in comparison to models with billions of trainable parameters, taking weeks to train.
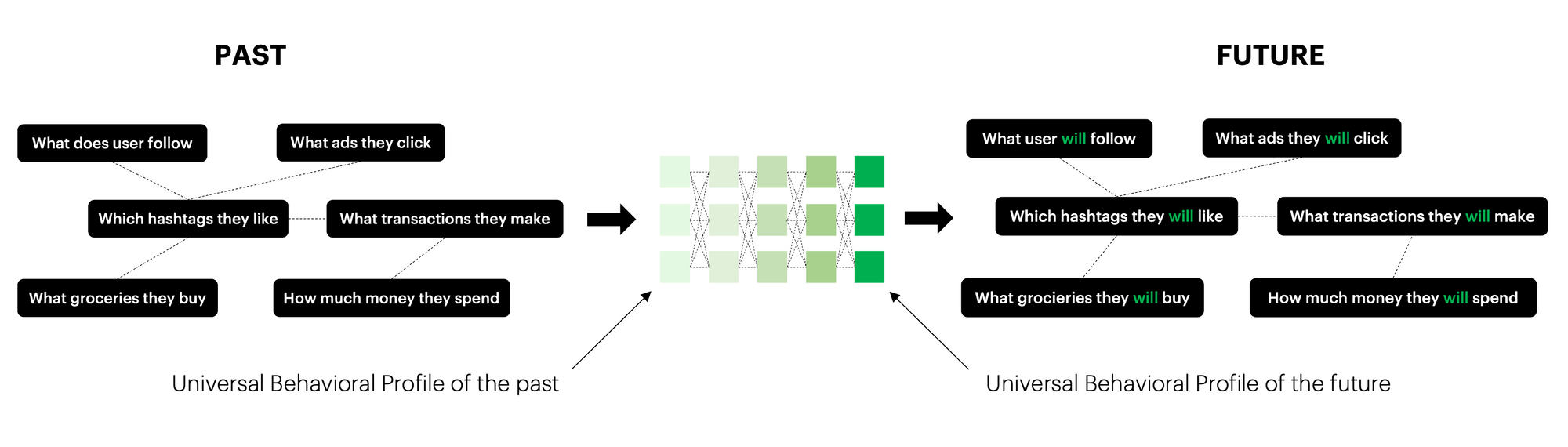
We can then fine-tune the pre-trained foundation model for many different tasks. In the recommendation task, we predict which products customers will buy. For churn prediction, we estimate which customers are likely to become inactive in the near future. We can also predict if the user will buy a given product, use services of some category, purchase something of a given brand, and so on.
Of course, these are only selected examples of what can be done with BaseModel, but in fact, methods used here are very universal. Taking part in many competitions, we tested Cleora+EMDE behavioral profiles in various tasks from different domains such as next destination prediction on Booking.com data, scientific papers subject area prediction on a large graph dataset, near real-time Tweets recommendation, or matching a product image to the description. In each of these tasks, we were in the top three together with big research labs like NVIDIA or DeepMind.

What is more, BaseModel is very easy to use with some common use cases available off the shelf. At the same time, there is a lot of room for custom configuration and creating personalized solutions. It is meant to be of help to data scientists by decreasing model development time. The repetitive part of the work, where a lot of issues and mistakes can arise, was automated. What’s left is the creative part of the process, where data scientists can use their knowledge to find the best model design and check hypotheses about data, customers, services, or products much quicker.
BaseModel in practice
But how does it look in practice? First, BaseModel retrieves event data from a database (e.g., ClickHouse, Snowflake, Redshift, BigQuery). The next step is the fit phase where we create functions that transform input data into behavioral profiles. We define what kinds of events and attributes we want to use and how to group them. For example, we can group product buys by customer. This way users are represented in terms of products they bought, and products are encoded to keep the notion of similarity as being bought by the same user. Analogically, we can group card transactions by user, products by session, and so on. As you can see, we have very easy fit phase configuration resulting in complex entity representations, with all the graph-based behavioral profiling magic going under the hood. What is important about the fit phase is that instead of storing hundreds of features per entity, we store small helper data structures and functions created based on provided data, that instruct how to transform them into features.
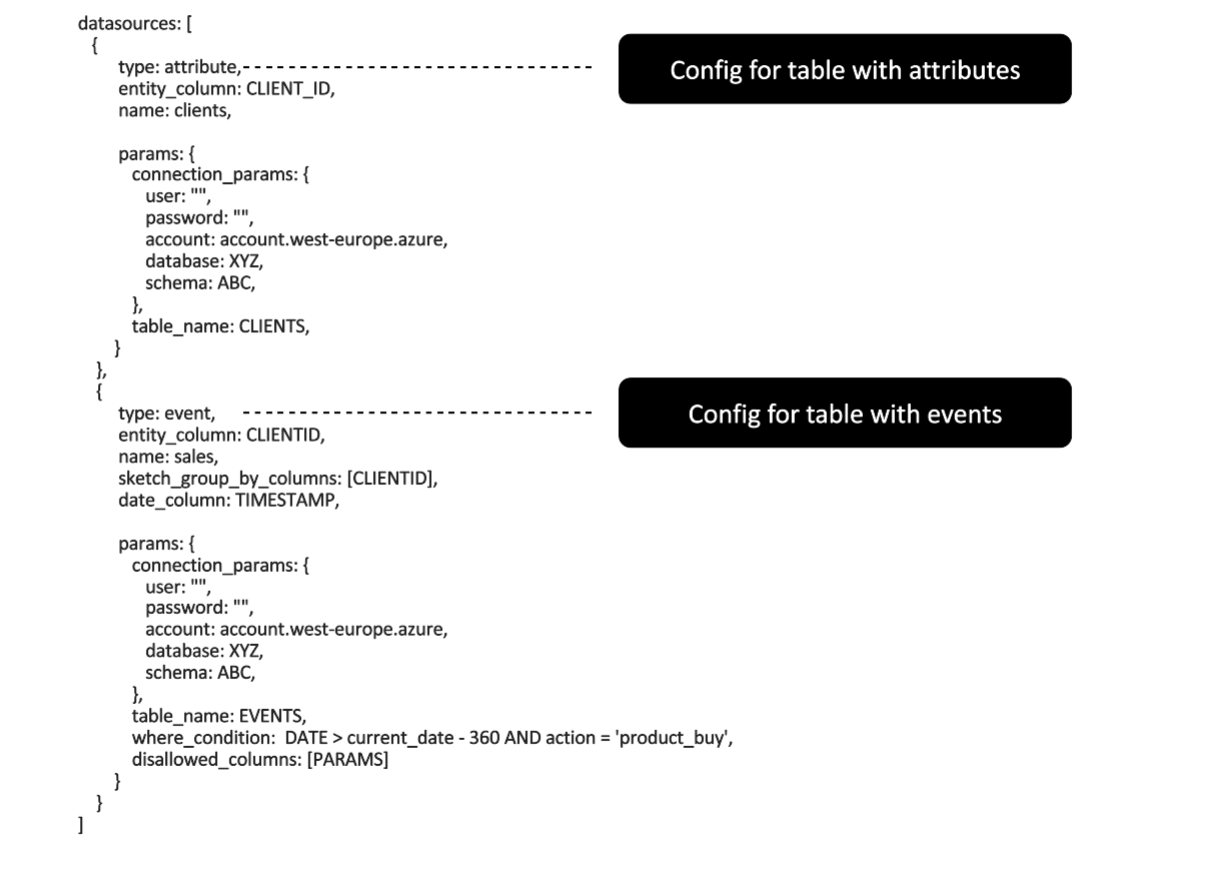
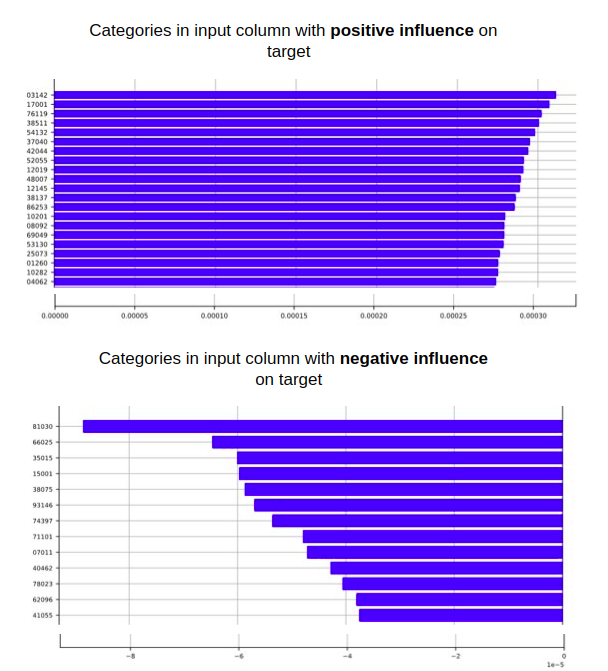
In model training phase data is streamed from a source and only a fraction of it is loaded into memory. Features are generated on-the-fly using feature transforms created during the fit phase. Resulting representations are used to train a model. In training configuration, we can easily set a target that we want to predict, together with model and training parameters. Additionally, the interpretability module shows how each table, column or value contributes to the final prediction
Data science projects need a considerable amount of time and effort to validate if a given approach fulfills business requirements. Also, event data are particularly difficult due to dataset size, real-time applications, and the need to keep the solution up to date with quickly changing conditions. We put an effort to create an ML copilot that will help data scientists with the time-consuming part of model development and make it much easier to validate solutions, and test different business scenarios. At the same time, we are driven by the need to keep the area of behavioral modeling in line with recent prominent approaches in AI research. We don’t overlook BaseModel's utility as a tool that can be used in production settings, but at the same time, our ambition is to push the frontier of AI-driven behavioral modeling.
