
Temporal data splits

Understanding human behavior is a complex and challenging task. Behavioral modeling domain spanning tasks such as recommendation, propensity-to-buy, or LTV, require solutions tailored to domain's specific requirements. However, solutions are often copy-pasted from other domains. In behavioral modeling, we aim to predict future behaviors based on user's past interactions. We recognize the importance of the temporal aspect that is shaping data in real-life settings, and we wanted to reflect it in our approach to data splitting.
The popular practice is to leave out some sub-set of users from model training to perform model validation and testing. This follows the technique used in other domains. Our aim was to adapt techniques that reflect how behavioral models are used in practice, where models are trained and battle-tested on the same customer base. There is no left-out set in real life, only customer history and customer future. Unlike our competitors, we followed this organic setting for behavioral tasks. The exact procedure is described in the BaseModel data split procedure section.
The second aspect we discuss in this blog post is improving the model training with dynamic time-splits. Behavioral models are based on the track of user interactions such as clicks, transactions, contacts with customer service, among others. For training purposes, there is a need to split available user information into two sets — the history and the future; interactions based on which we want to predict and interactions we want to predict. We created a method that enriches training data by creating endless numbers of splits. This is related to our view on the time-based aspects of behavioral data but was made possible thanks to our approach to creating input features — users' behavioral representations. Thanks to our proprietary algorithms we can create model input features on-the-fly from raw data. Standard approaches relying on pre-computing and storing many hand-crafted features lack this kind of flexibility. Let's consider 50k features in float32 for 10M users and re-computing them 4 times a day. It will take:
4 (bytes) ×50000 (features)×10000000 (users) ×4 (times a day) ×365 (days) = 2,92 petabytes
We can easily see that adapting this kind of approach to compute features for each split between two events for each user is infeasible. We show the details of our training data split technique in BaseModel training procedure section and our alternative approach to feature engineering in Creating features on-the-fly section.
BaseModel data split procedure
In BaseModel, we introduce the concept of temporal data splits. Instead of randomly dividing datapoints into three distinct sets — train, validation, and test — we divide data in time. First, we establish the dataset starting point, which we will refer to as data start date. From now on, we will only consider data after this date. We can configure it to be the date of the first available data point or, when working in real-life settings, we may choose to use a subset of available data, e.g., only data from the last year.
Next, we need to configure the validation start date. Events after this date are not available for training, and we use them to create targets for validation. Subsequently, we configure the test start date. Data after this date are excluded both from training and validation. However, when creating model input we always consider data starting from the data start date. This means that in the case of validation, we use all available data up to the validation start date to create input features and events after the validation start date are what we want to predict. The prediction target, the ground truth for validation is created based on events starting at the validation start date. We check the next n consecutive days for the event we want to predict, e.g., if the product of a given brand or category was bought. This time-window must fit within the period before the test start date to prevent data leakage. To obtain validation metrics, we compare model results with such created targets. Similarly, in testing scenario all data after the data start date to the test start date are used to create an input to the model. The following n days after the test start date are used to create targets and measure model performance.
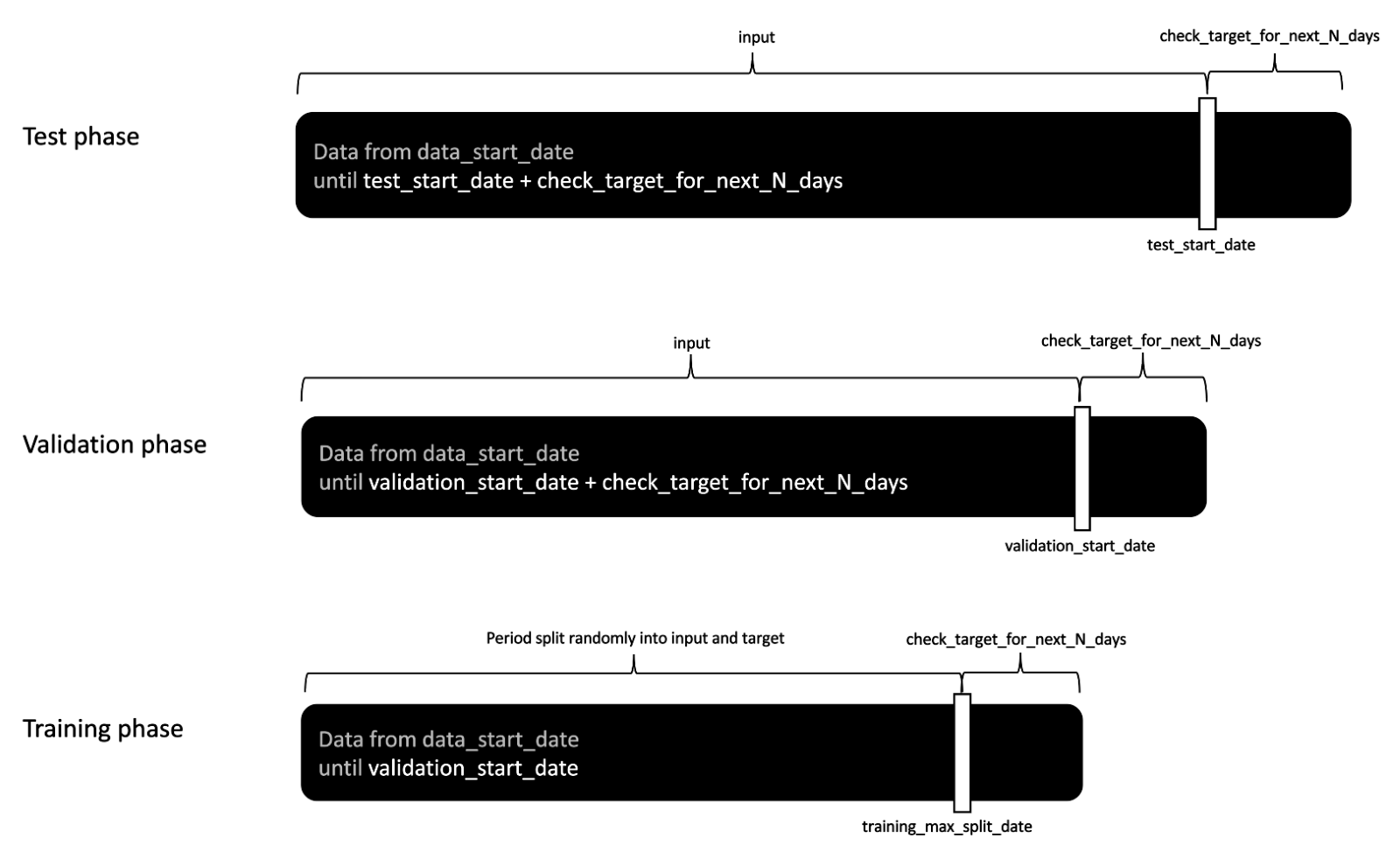
This technique splits data in time rather than by users or sessions. We have chosen this approach as we believe it best mimics the real-life scenarios, where models are trained on available historical data and inference is made on events that occurred after training. What is important, in production settings the predictions are made based on the same data source that was used to create the training set. We train a model using the customers' histories that are stored in a data warehouse, and when a customer interacts with the ecosystem, we want to use available history to provide predictions. When we evaluate a model, we should recreate these settings to best represent the context in which the model will be used. When a different set of users is considered in training and different in validation this creates artificial division devoid of temporal aspects. A simplified, naïve approach of a user-holdout set is also on our roadmap for quick checks of model stability during subsequent training sessions.
BaseModel training procedure
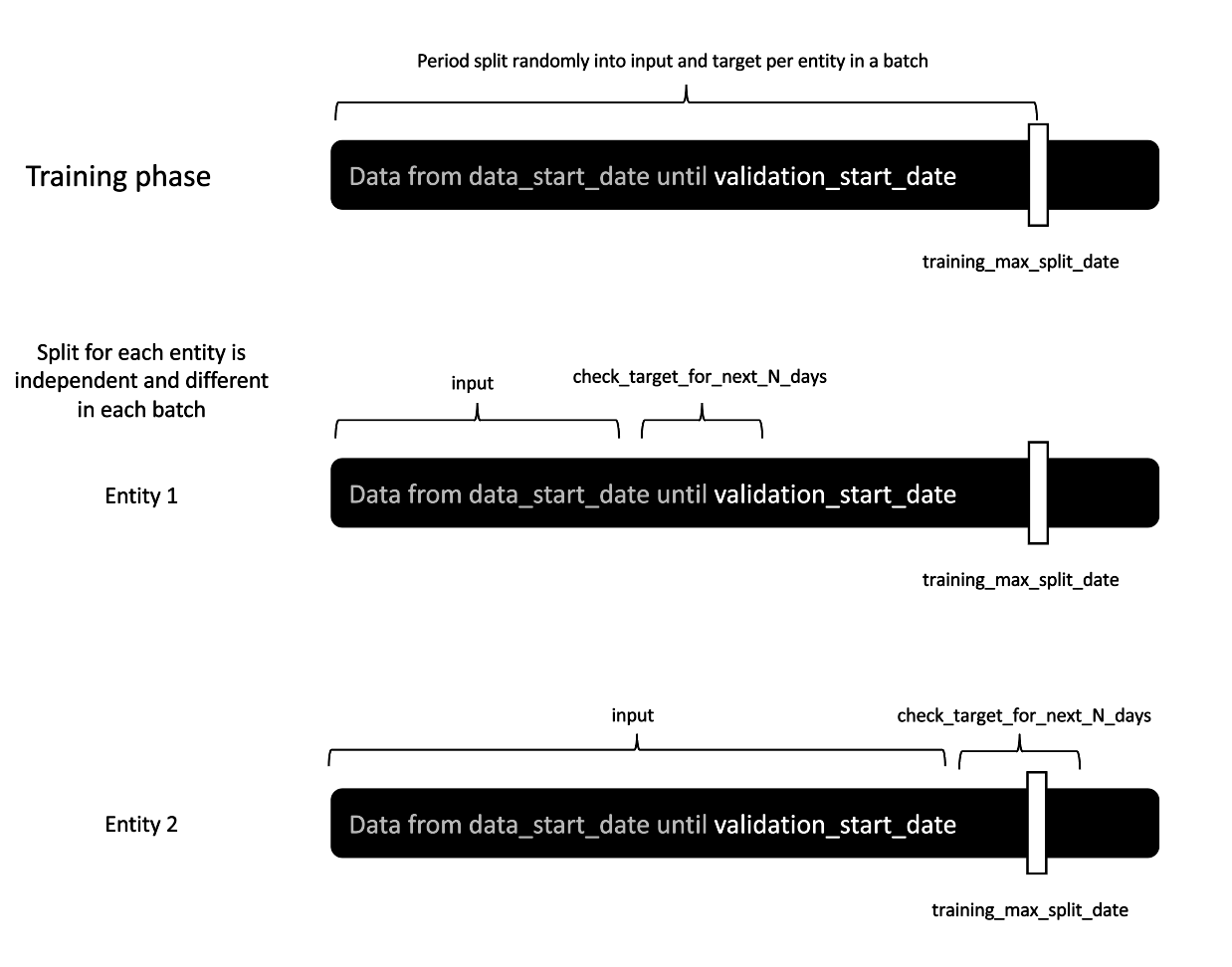
In training, we consider only data after the data start date but before the validation start date. Whereas in validation we use a fixed date after which we create targets, here, we consider all events that fit into the time window intended for training. Next, we use event timestamps to select data split points, that divide events into two chunks — one to create input and one for targets. What we need to take into consideration is that the latest possible split point plus the number of days considered to create a target must fit before the validation start date. It is computed as follows:
training_max_split_date = validation_start_date – 1 – check_target_for_next_N_days
This data split selection method prevents data leakage — events seen in training will not be used to create targets for validation.
When we consider a single user’s history, all events before the split point are used to create input features, and events that occurred during n days after the split point are used to create the model’s target. In standard approaches, a single predefined threshold is set to divide data for training. With our method, multiple split points can be selected from a single user's history. This way we can augment data by creating multiple data points based on one user history.
Recommendations
Although the described data splitting procedures are a general pattern we apply in various tasks from the behavioral modeling domain, in the case of recommendations, we propose a slightly altered procedure. Instead of considering the next n days to check the target we use the next basket. We observed that this method can improve recommendation system results. However, we provide an option to train recommenders on data beyond one basket if needed. In this case, all data from the next n days are used and the additional parameter allows you to weigh events with respect to their recency. In the recommendation task, promoting the model's decisions that are more in line with the most recent future can boost performance. We can hypothesize that user needs expressed in recommendations depend not only on long-term dependencies but also on short-term context, which is why predicting the nearest future may improve the quality of recommendations.
Threshold sampling
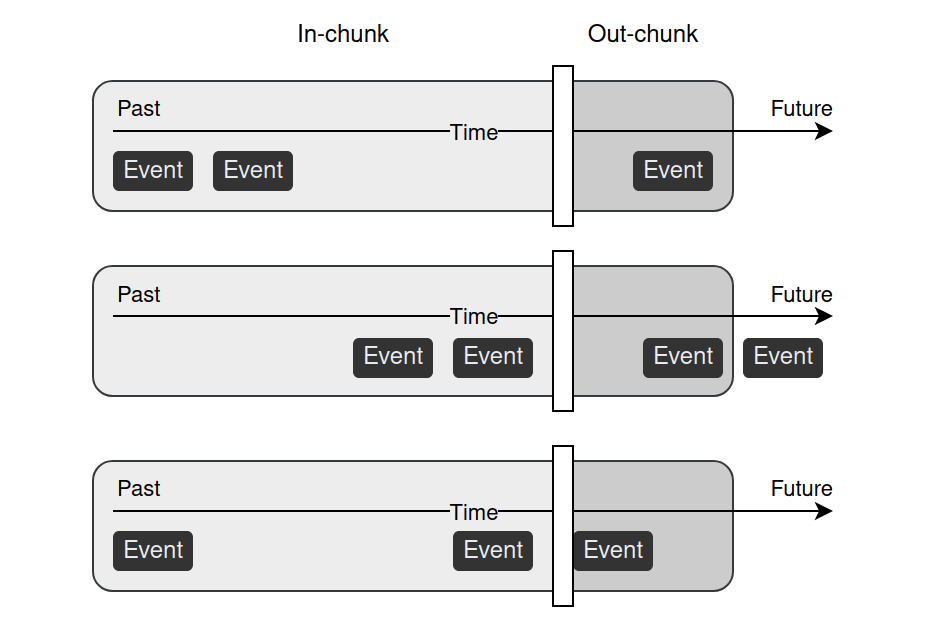
We propose two threshold sampling methods: random sampling and valid sampling. In both cases, we randomly select timestamps from a user’s events, which divides data into two chunks: in-chunk for input and out-chunk for target. However, the valid sampling strategy requires at least one event in the out-chunk. Whereas random sampling does not have to fulfill this condition — out-chunks with no events are allowed. This can be a desired behavior in tasks like churn prediction, where we predict if a user will make a purchase in some predefined time window.
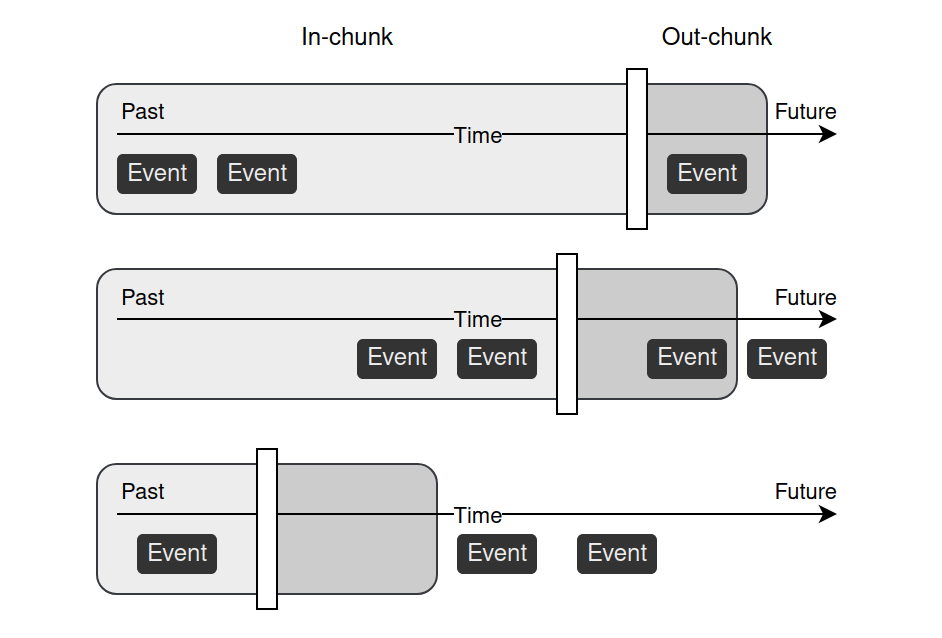
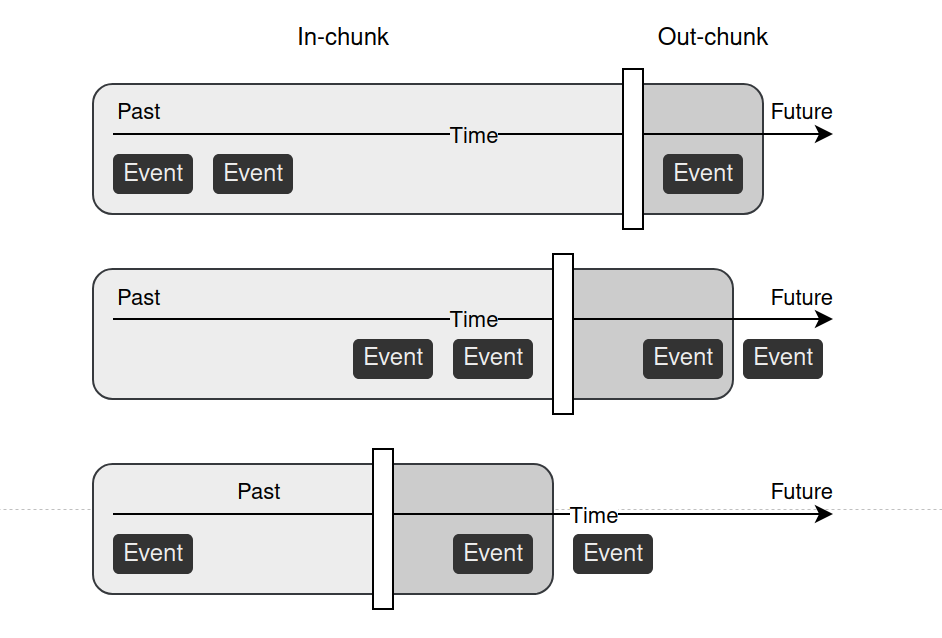
We provide experiments where we compare these sampling strategies with the standard static approach. In the static approach, one threshold is selected, the same for every user, with the possibility of empty out-chunks. We use two publicly available datasets: Kaggle eCommerce dataset and Kaggle H&M dataset. Described sampling strategies are tested in three different tasks. In churn prediction, the model is trained to predict no action in the next 14 days. The propensity model predicts the probability a user will purchase an item from one of the selected brands in the next 14 days. In the recommendation task, the model is trained to predict items the user will be interested in over the next 7 days. In the case of churn and propensity prediction, we compare three strategies: static, random, and valid. The evaluation metrics for these tasks are the Area Under the Receiver Operating Characteristic Curve (AUROC) and Average Precision (AP). In the case of recommendation, we only consider static and valid sampling as we want the model to always recommend something. To evaluate the recommendation model we use Hit Rates at the top 1 and top 10 products returned by the model (HR@1 and HR@10 respectively), as well as Precision at the top 10 products (Prec@10) and mean Average Precision at the top 12 products (mAP@12).
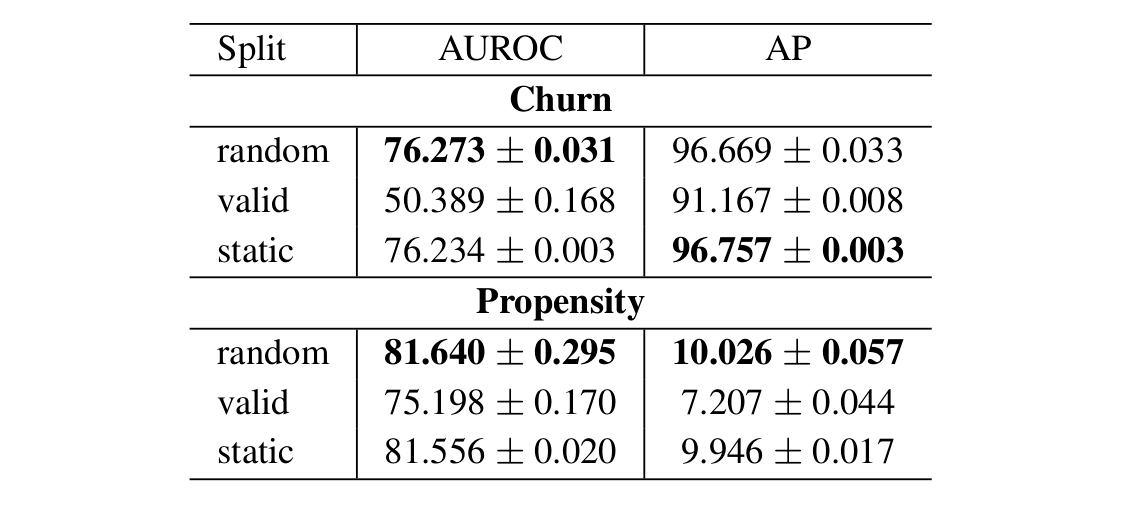
In propensity and churn tasks, the valid sampling method results in worse model performance than other tested methods. Since valid sampling excludes empty out-chunks it results in a distribution that is skewed towards active users. In churn prediction, it explicitly interferes with the task which is to predict user inactivity. However, propensity task results also promoted sampling methods that enable an empty time window at a target. This shows that there is information value in users' inactivity and promotes target created with less purposeful interference with data. On the other hand, the recommendation task promotes valid sampling over static methods. This suggests that data enrichment with additional samples provides better model results.

Handcrafted features
These training and evaluation procedures stem from how we understand behavioral modeling problems more generally. The approach to feature engineering plays a decisive role here. Usually, a user is represented by a large vector stored in a feature store. Creating and storing this kind of representation is costly, which makes it hard to create multiple representations for a single user.
Consider a toy example of recommendation settings. We have information about a user: the unique identifier and (optionally) some attributes like gender or age. We have a history of user interactions with a service, e.g., bought products, page views, add to carts, and so on. We also may have product attributes, like category, price, size, or brand. The task will be to predict what the user will buy next. To train any machine learning models we need to find a way to represent user history and create input features.
In a naive approach, we may see a list of one-hot encoded products from user history, the average price of bought products, a list of categories the user made a purchase in, favorite brand. These vectors in fact consist of many handcrafted features which are precomputed and kept in the feature store. Multiple splits will result in a radically increased data size that must be stored. Also, aggregated features would need to be re-computed for each new data split to prevent information leakage. For example, if we compute the average price of historical purchases based on one data split and use the same average price for the earlier split, part of the information from the target will be available on the input.
Creating features on-the-fly
With BaseModel, we use our proprietary algorithms to create user representations — Universal Behavioral Representations. These representations are created by combining information from user interactions (events), metadata, and available context into a fixed-size structure. We do not need to store representation for each user. What we store are transform functions learned from data, that provide the mapping between events in user history and fixed-size user representation. We can then select during training an arbitrary set of events and create user representation on the fly. For details see, Project BaseModel and EMDE Illustrated blog posts.
This method of event data representation is what made our experiments with different data splitting techniques possible, through a fast and lightweight features engineering pipeline. With this flexibility, we were able to augment data by creating multiple data splits from a single user history.